A KlattGrid represents the source-filter model as a function of time. It consists of a number of tiers that model aspects of the source and the filter, and the interaction between source and filter. The KlattGrid implements a superset of the speech synthesizer described in figure 14 by Klatt & Klatt (1990).
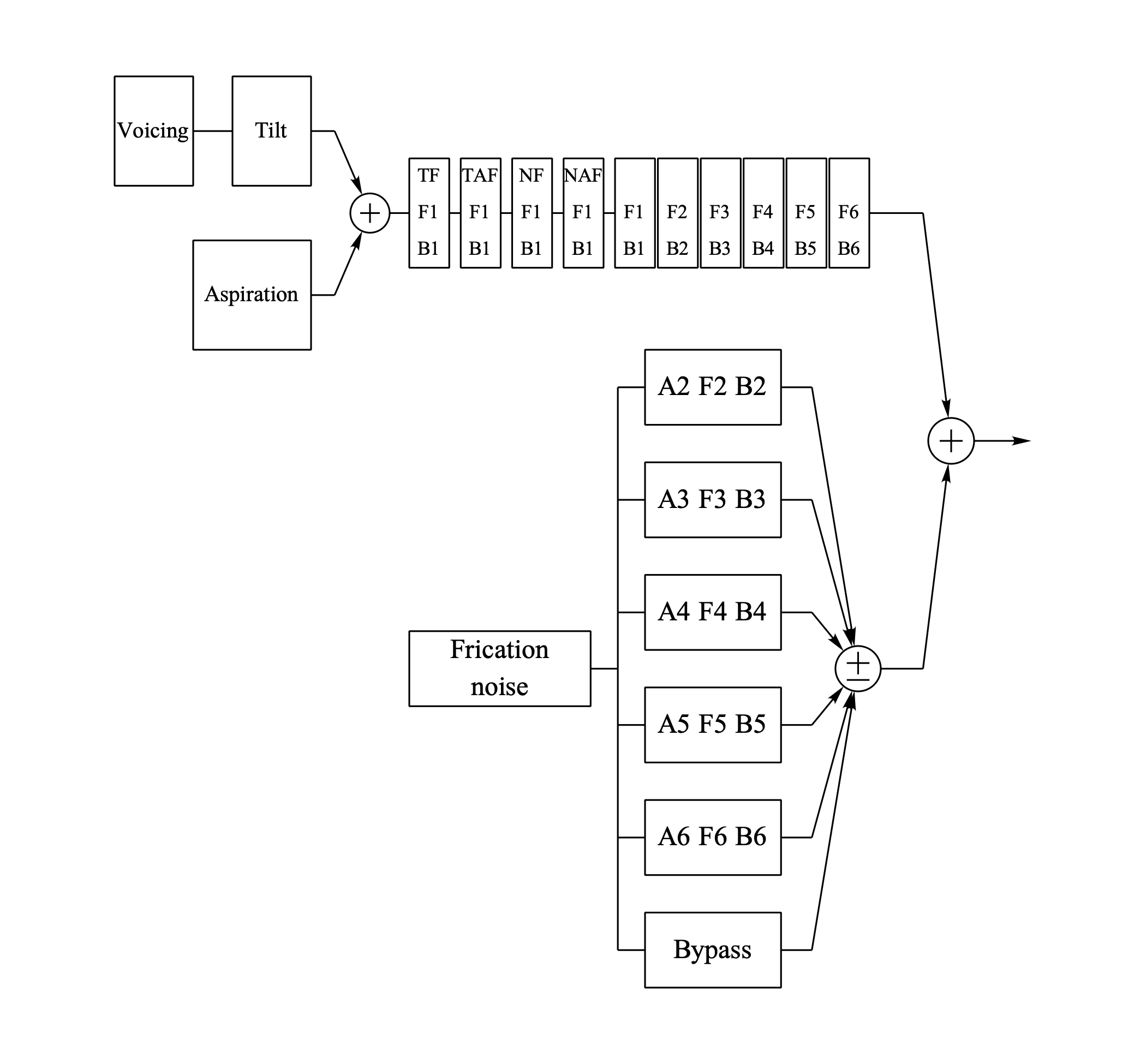
The following drawing represents a cascade synthesizer with six oral formants, one nasal formant, one nasal antiformant, one tracheal formant, one tracheal antiformant and six frication formants.
In the next picture a parallel synthesizer branch is used instead of the cascade one.
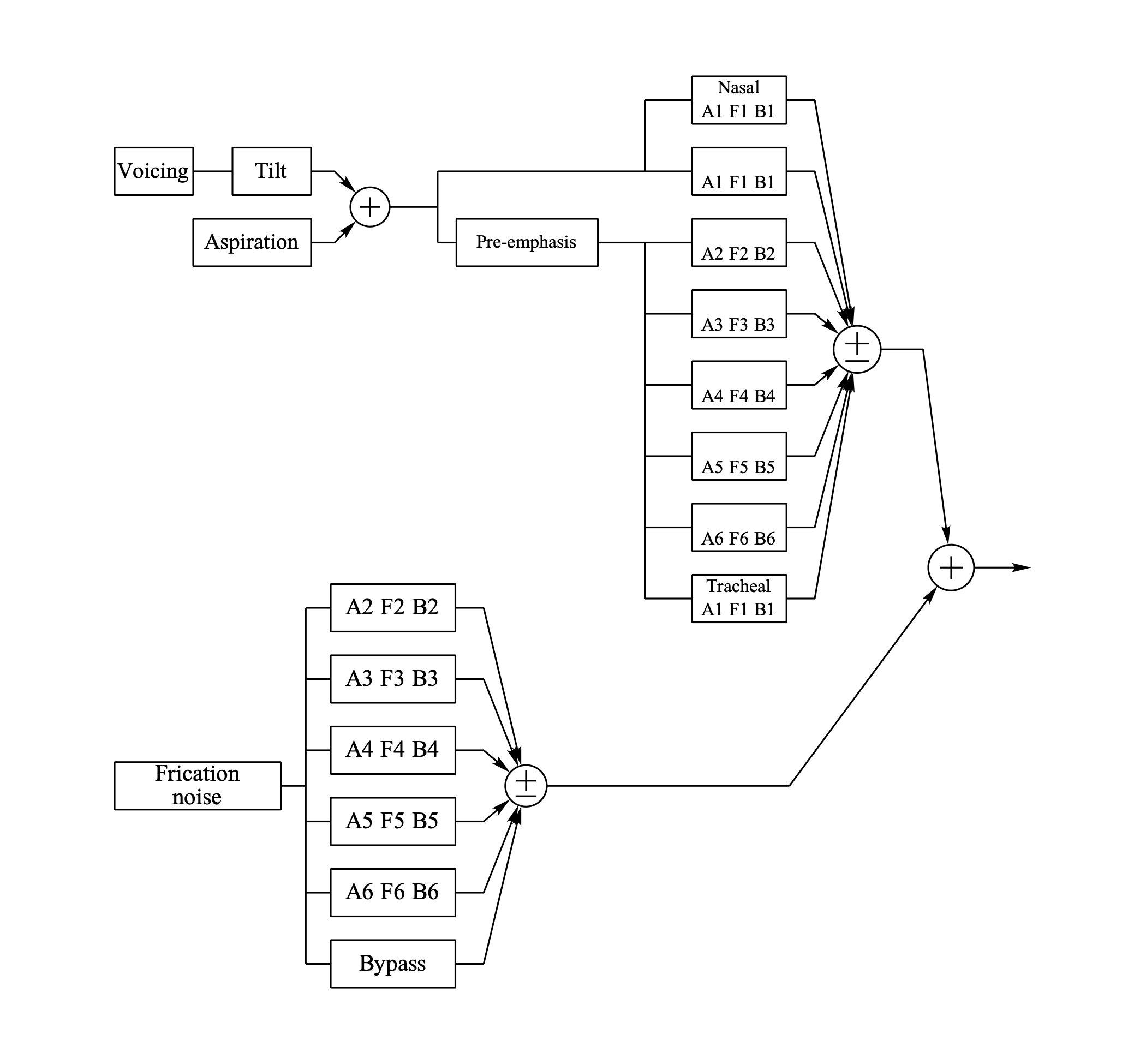
All parameters in the synthesizer are represented by separate tiers.
The source
The source is modelled by the following tiers:
- Pitch
- models fundamental frequency (in Hertz).
- Flutter
- models a kind of “random” variation of the pitch (with a number between zero and one).
- Voicing amplitude
- models the maximum amplitude of the glottal flow (in dB SPL).
- Open phase
- models the open phase of the glottis (with a number between zero and one). If the tier is empty, a default of 0.7 will be used.
- Power1, Power2
- model the shape of the glottal flow function flow(t)=tpower1−tpower2 for 0 ≤ t ≤ 1. To make glottal closure possible, power2 has to be larger than power1. If the power1 tier is empty, a default value of 3 will be used. If the power2 tier is empty, a default of 4 will be used.
- Collision phase
- models the last part of the flow function with an exponential decay function instead of a polynomial one. More information about Power1, Power2, Open phase and Collision phase can be found in the PointProcess: To Sound (phonation)... manual.
- Spectral tilt
- models the extra number of dB the voicing spectrum should be down at 3000 Hertz.
- Aspiration amplitude
- models the (maximum) amplitude of the noise generated at the glottis (in dB SPL).
- Breathiness amplitude
- models the maximum breathiness noise amplitude during the open phase of the glottis (in dB SPL). The amplitude of the breathiness noise is modulated by the glottal flow.
- Double pulsing
- models diplophonia (by a fraction between zero and one). Whenever this parameter is greater than zero, alternate pulses are modified. A pulse is modified with this single parameter in two ways: it is delayed in time and its amplitude is attenuated. If the double pulsing value is a maximum and equals one, the time of closure of the first peak coincides with the opening time of the second one.
The vocal tract filter
The filter is modelled by a number of FormantGrid's. For parallel synthesis the formant grids that normally only contain formant frequency and formant bandwidth tiers, have been extended with amplitude tiers. Amplitudes values are in dB. The following formant grids can be used:
- Oral formants
- represent the “standard” oral resonances of the vocal tract.
- Nasal formants
- model resonances in the nasal tract. Because the shape of the nasal tract does not vary much during the course of an utterance, nasal formants tend to be constant.
- Nasal antiformants
- model dips in the spectrum caused by leakage to the nasal tract.
Interaction between source and filter
The interaction between source and filter is modelled by two formant grids.
- Tracheal formants
- model one aspect of the coupling of the trachea with the vocal tract transfer function, namely, by the introduction of extra formants (and antiformants) that sometimes distort vowel spectra to a varying degrees. According to Klatt & Klatt (1990), the other effect of tracheal formants is increased losses at glottal termination which primarily affect first-formant bandwidths.
- Tracheal antiformants
- model dips in the spectrum caused by the trachea.
- Delta formants
- The values in this grid model the number of hertz that the oral formants and/or bandwidths change during the open phase of the glottis. Klatt & Klatt (1990) distinguish four types of source-filter interactions: an F1 ripple in the source waveform, a non-linear interaction between the first formant and the fundamental frequency, a truncation of the first formant and tracheal formants and antiformants.
The frication section
The frication section is modelled with a frication formant grid, with formant frequencies, bandwidths and (separate) amplitudes (dB), a frication by-pass tier (dB) and an amplitude tier (dB SPL) that governs the frication noise source.
A minimal synthesizer
The following script produces a minimal voiced sound. The first line creates the standard KlattGrid." The next two lines define a pitch point, in Hz, and the voicing amplitude, in dB. The last line creates the sound.
Create KlattGrid: "kg", 0, 1, 6, 1, 1, 6, 1, 1, 1
Add pitch point: 0.5, 100
Add voicing amplitude point: 0.5, 90
To Sound
The following script will produce raw frication noise. Because we do not specify formant amplitudes, we turn off the formants in the parallel section.
Create KlattGrid: "kg", 0, 1, 6, 1, 1, 6, 1, 1, 1
Add frication amplitude point: 0.5 ,80
Add frication bypass point: 0.5, 0
To Sound (special): 0, 0, 44100, "yes", "no", "yes", "yes", "yes", "yes",
... "Powers in tiers", "yes", "yes", "yes",
... "Cascade", 1, 5, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, "yes"
Changes
In Praat versions before 5.1.05 the values for the oral / nasal / tracheal formant amplitudes and frication bypass amplitude had to be given in dB SPL; now they are in real dB's, i.e. 0 dB means no change in amplitude. You can calculate new values from old values as: new_value = old_value + 20*log10(2e-5). This means that you have to subtract approximately 94 dB from the old values.
Links to this page
© David Weenink 2014-01-17