
R.J.J.H. van Son & Louis C. W. Pols
Institute for Phonetic Sciences / IFOTT, University of Amsterdam, Herengracht
338,
NL-1016CG Amsterdam, The Netherlands, E-mail: {rob, pols}@fon.let.uva.nl
Reduction causes changes in the acoustics of consonant realizations that affect their identification. In this study we try to identify some of the acoustic parameters that are correlated with this change in identification. Speaking style is used to manipulate the degree of reduction. Pairs of otherwise identical intervocalic consonants from read and spontaneous utterances are presented to subjects in an identification experiment. The resulting identification scores are correlated to five different acoustical measures that are affected by the amount of consonant reduction: Segmental duration, spectral Center of Gravity, intervocalic sound energy difference, intervocalic F2 slope difference, and the amount of vowel reduction in the syllable kernel. The identification differences between the read and spontaneous realizations are compared with the differences in each of the acoustic measures. It showed that only segmental duration and the spectral Center of Gravity are significantly correlated to identification scores.
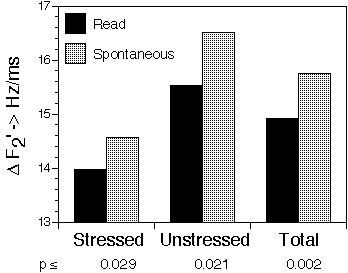
From an earlier study on acoustic consonant reduction in spontaneous versus read speech ([8],[10]) we selected four global acoustic measures of consonant reduction: Segment duration, the spectral Center of Gravity (i.e., the "mean" frequency, weighted by spectral power), the Intervocalic Sound-Energy difference (i.e., VCV Energy Difference, the difference in total sound power between consonants and their neighboring vowels), and the difference between the F2 slopes at the CV and VC borders of the consonant. All of these measures are correlated to speaking style differences and vowel reduction and might be perceptually relevant ([8],[10]). It has been shown that neighboring vowels too play a role in the identification of consonants ([9]). Therefore, the degree of vowel reduction might also influence the identification of neighboring consonants. To assess this influence, we added the distance in the F1/F2 plane (in semitones) between the kernel of the tautosyllabic vowel (i.e., the point with the most extreme F1 or F2 value) and the center of vowel reduction, i.e. (250, 1300) Hz for this speaker. This distance quantifies the contrast in the vowel system [3].
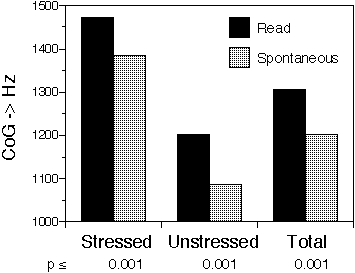
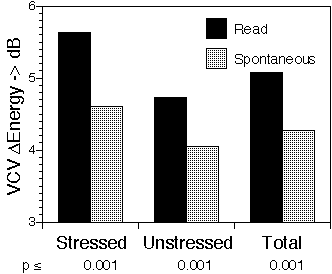
The first three of these acoustic parameters (segmental duration, spectral Center of Gravity, and Intervocalic Sound-Energy difference are linked to the prosodic structure of the utterance [10]. The formant related acoustic measures are linked to the articulatory structure of the syllables.
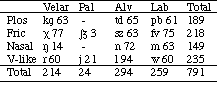
Table 1. Dutch consonants used in this paper and the number of matched Read/Spontaneous VCV pairs (ignoring voicing differences).
22 Dutch subjects, all native speakers of Dutch, were asked to identify these 1582 intervocalic consonant realizations in their original VCV context (791 pairs, 308 stressed, 483 unstressed). The outer 10 ms of the VCV tokens were removed and smoothened with 2 ms Hanning windows to prevent interference from the adjacent consonants and transient clicks. The order of presentation was (pseudo-)random and different for each subject. The subjects had to select the Dutch orthographic symbol that corresponded to the sound heard on a computer CRT screen (this causes no ambiguity in Dutch).
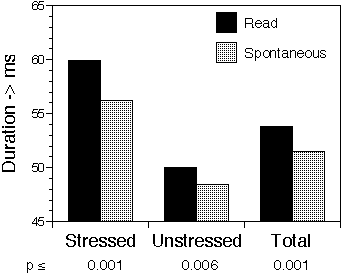
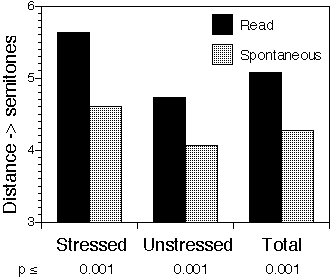
In a first approximation, identification rates in a listening experiment can be modeled by a binomial probability distribution. For 22 responses to each stimulus it can be deduced that the standard deviation of the difference in the number of correct responses between members of read/spontaneous consonant pairs will be ~3 responses. This "error" has the same order of magnitude as the difference itself. The acoustical measurements add their own errors which too can be expected to be large with respect to the differences between speaking styles. For instance, segmentation errors, and therefore, durations, are comparable to a single pitch period, i.e., ~ 5 ms. However, the mean difference in duration between read and spontaneous consonants is less than 5 ms (see figure 1).
Table 2. Example of frequency tables used to investigate the correlation
between acoustic measurements and correct identification. Table entries are
numbers of pairs with the sign of the difference between Read and Spontaneous
realizations as indicated. Frequencies expected from the marginal distributions
are given in brackets (Row Total . Column Total / Total, e.g.,
263.177/609=76.44). The Odds are the sum of the diagonal terms divided by the
sum of the off-diagonal terms, i.e., (110+279)/(67+153)=1.768 and
(76.44+245.44)/(100.56+ 186.56) =1.121 (found and expected, respectively). The
odds ratio is the odds found divided by the odds expected (i.e.,
1.768/1.121=1.577). Also: p<=0.001,
![]() 2=35,
2=35,
![]() =1, Contingency = 0.23. R: Read speech, S: Spontaneous speech, Rows: Duration,
columns: identification rate.
=1, Contingency = 0.23. R: Read speech, S: Spontaneous speech, Rows: Duration,
columns: identification rate.
R < S
|
R
> S
|
Total
| |
| R
< S
|
110
(76.44)
|
153
(186.56)
|
263
|
| R
> S
|
67
(100.56)
|
279
(245.44)
|
346
|
| Total
|
177
|
432
|
609
|
The global error rates for Spontaneous and Read realizations are displayed in
figure 6. The error rates are considerably larger for Spontaneous than for Read
speech for both Stressed and Unstressed realization. For both speaking styles,
the error rate was larger for unstressed than for stressed realizations
(p<=0.001,
![]() 2>38,
2>38,
![]() =1). We want to know to what extent a change in the value of each of the
acoustic markers for consonant reduction is predictive for a change in
identification errors. That is, when a marker indicates reduction, can we
expect higher error rates and vice versa? This is analyzed as a correlation
between the signs of the changes in the marker values and in the error
rates due to speaking styles.
=1). We want to know to what extent a change in the value of each of the
acoustic markers for consonant reduction is predictive for a change in
identification errors. That is, when a marker indicates reduction, can we
expect higher error rates and vice versa? This is analyzed as a correlation
between the signs of the changes in the marker values and in the error
rates due to speaking styles.
In figure 7 the result of this analysis is displayed as the ratio of the odds for predicting the correct direction of change using the observed and a random pairing of the identification scores and marker values. This odds ratio is by definition normalized for the mutual correlation with speaking style of both markers and error rates (i.e., the marginal distributions).
It shows that the correlation between the sign of the acoustic measurement and the identification rate is only statistically significant for the segmental duration and spectral Center of Gravity. It is clear that knowing either the direction of change in segmental duration or the Center of Gravity increases the odds ratio for guessing the correct change in identification rates to a maximum of 1.6. The perceptual relevance of the other markers for consonant identification seems to be marginal, at most.
It is evident that the predictive powers of segmental duration and spectral Center of Gravity are limited. The odds ratios are well below 2. That is, knowing the direction of change (i.e., reduction or not) in either of these acoustic factors not even doubles the odds for correctly predicting the direction of change in identification (i.e., better or worse).
Another cause for a weak predictive power of individual acoustical factors is that consonant identification does not depend critically on a single acoustical feature. Many factors combine to determine consonant identity. Most of these factors too will be influenced by speaking style, and consonant reduction. The effect is again, to weaken the correlation between any single acoustic parameter and consonant identification scores. This is especially so for indirect parameters like the formant contrast that measures the amount of vowel reduction. The effects of the amount of vowel reduction on the identification of neighboring consonants might just have been too weak to measure.
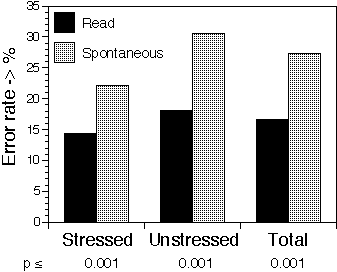
Figure 6. Mean error rates of the consonant stimuli, split on speaking style (read and spontaneous) and syllable stress. The significance levels of the differences between read and spontaneous realizations are calculated using McNemar's test.
There remains the question of how a longer duration and a higher spectral Center of Gravity can help consonant identification. In both cases, more information is available to the listener. It is straightforward that longer segments can carry more articulatory information, and they apparently do so. A higher frequency of the spectral Center of Gravity generally indicates a more level spectral tilt of the sound source at medium and higher frequencies [10]. That is, there is more energy at the higher frequencies and, therefore, more articulatory information in the signal. The fact that "reduction" of both factors actually reduces consonant identification in our experiment indicates that both duration and spectral tilt are "information limiting" in normal speech.
If the other acoustic parameters, Intervocalic Sound Energy difference, F2 slope difference and the formant contrast of the tautosyllabic vowel, did affect consonant identification, their values were either too erratic to give rise to discernible effects, or their effects were too small to be resolved by our experiment.
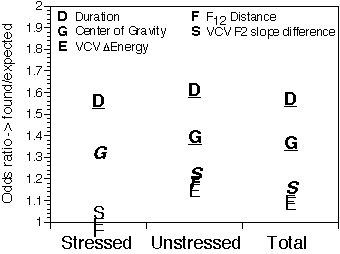
Figure 7. Odds ratios between acoustical measurements and
identification rates, split on syllable stress. Underlined: p<=0.001,
![]() 2 > 13,
2 > 13,
![]() = 1, Italic: p<=0.05,
= 1, Italic: p<=0.05,
![]() 2 > 3.89,
2 > 3.89,
![]() = 1
= 1