|
Creating a glottal source signal for speech synthesis involves creating a PointProcess, which is a series of time points that should represent the exact moments of glottal closure.
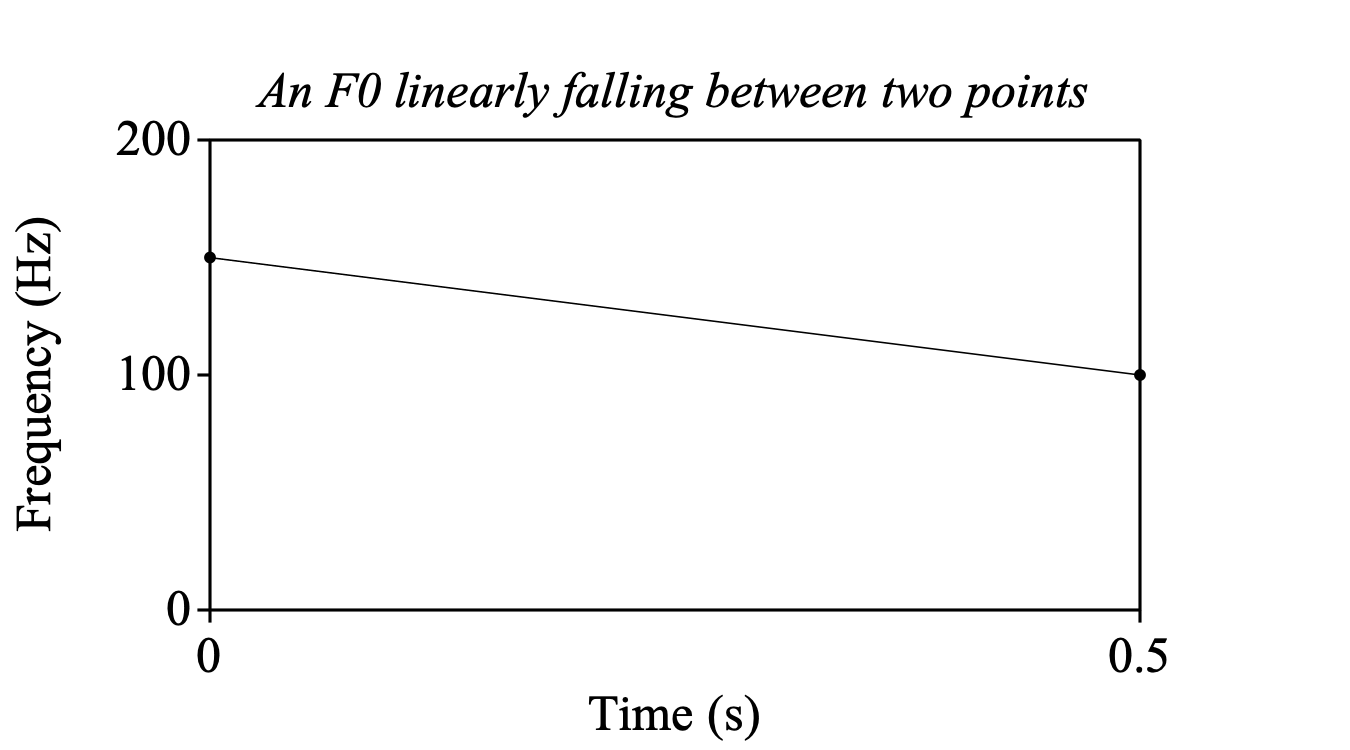
You may want to start with creating a well-defined pitch contour. Suppose you want to create a sound with a duration of half a second with a pitch that falls from 300 to 200 Hz during that time. You first create an empty PitchTier by choosing Create PitchTier... from the New menu (I call this PitchTier “empty” because it does not contain any pitch information yet); you may want to name the PitchTier “source” and have it start at 0 seconds and end at 0.5 seconds. Once the PitchTier exists and is selected, you can View & Edit it to add pitch points (pitch targets) to it at certain times (or you choose PitchTier: Add point... from the Modify menu repeatedly). You could add a pitch point of 150 Hz at time 0.0 and a pitch point of 100 Hz at time 0.5. In the PitchTier window, you can see that the pitch curve falls linearly from 150 to 100 Hz during its time domain:
You can hear the falling pitch by clicking on the rectangles in the PitchTier window (or by clicking Play pulses, Hum, or Play sine in the Objects window).
From this PitchTier, you can create a PointProcess with PitchTier: To PointProcess. The resulting PointProcess now represents a series of glottal pulses. To make some parts of this point process voiceless, you can use PointProcess: Remove points between.... It is advisable to make the very beginning and end of this point process voiceless, so that the filtered sound will not start or end abruptly. In the following example, the first and last 20 ms are devoiced, and a stretch of 70 ms in the middle is made voiceless as well, perhaps because you want to simulate a voiceless plosive there:
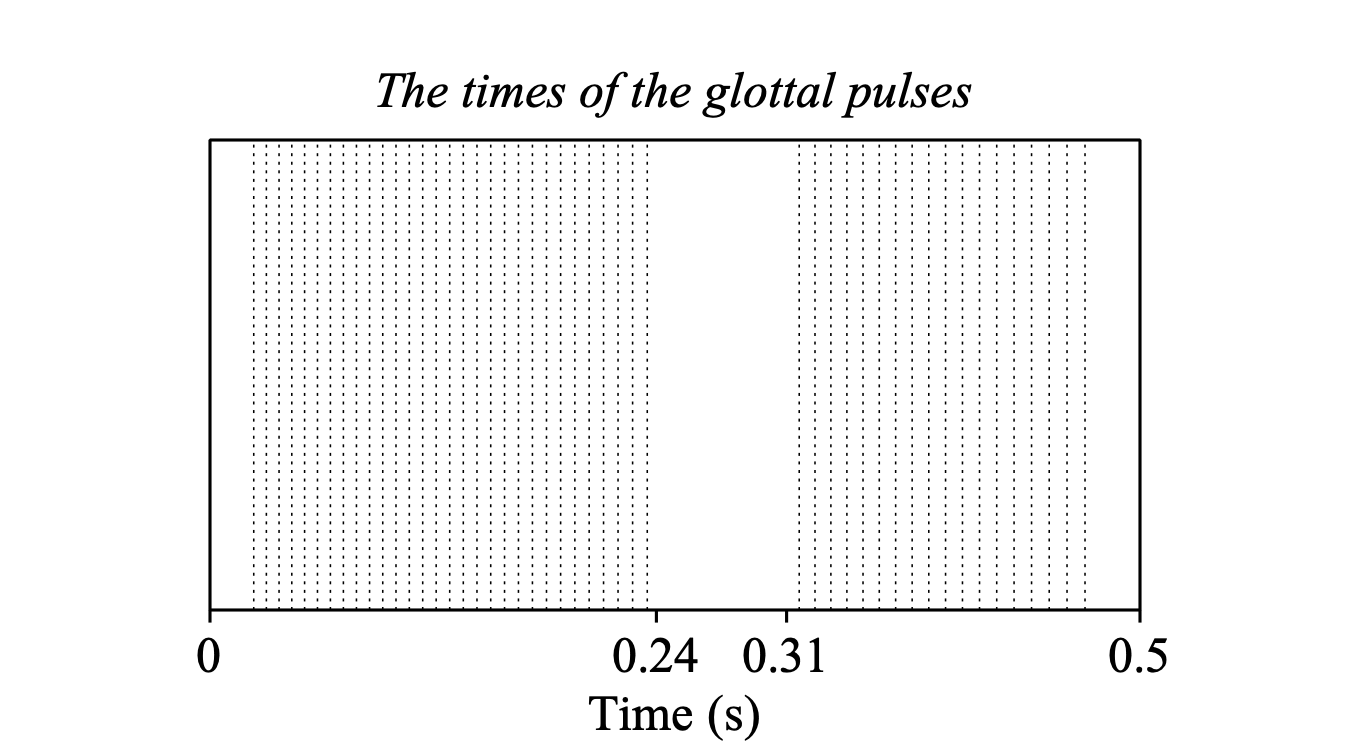
Now that we have a glottal point process (a glottal pulse train), the only thing left is to turn it into a sound by choosing PointProcess: To Sound (phonation).... If you use the standard settings of this command (but with Adaptation factor set to 0.6), the result will be a Sound with reasonable glottal flow derivatives centred around each of the original pulses in the point process. You can check this by selecting the Sound and choosing View & Edit:
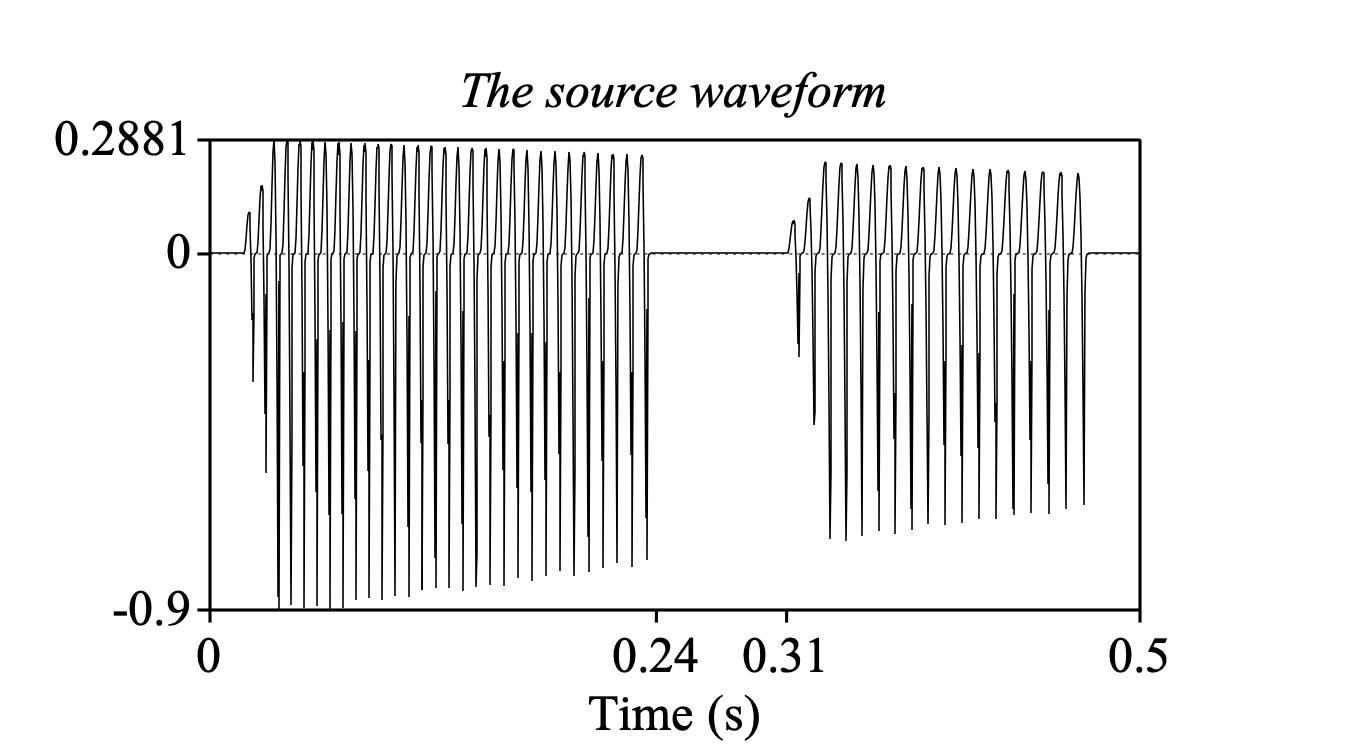
You will also see that the amplitude of the first two glottal wave shapes of every voiced stretch is (realistically) somewhat smaller than the amplitudes of the following wave shapes; This is the result of setting Adaptation factor to 0.6.
What you have now is what we call a glottal source signal. It does two things: it contains information on the glottal flow, and it already takes into account one aspect of the filter, namely the radiation at the lips. This combination is standard procedure in acoustic synthesis.
The glottal source signal sounds as a voice without a vocal tract. The following section describes how you add vocal-tract resonances, i.e. the filter.
In a clean Praat script, the procedure described above will look as follows:
pitchTier = Create PitchTier: “source”, 0, 0.5
Add point: 0.0, 150
Add point: 0.5, 100
pulses = To PointProcess
Remove points between: 0, 0.02
Remove points between: 0.24, 0.31
Remove points between: 0.48, 0.5
source = To Sound (phonation): 44100, 0.6, 0.05, 0.7, 0.03, 3.0, 4.0
removeObject: pitchTier, pulses
selectObject: source
© ppgb 20140421