The Gradual Learning Algorithm predicts the development
of first- and second-language phonological contrasts
Paola Escudero, escuderopaola@hotmail.com
Paul Boersma, paul.boersma@hum.uva.nl
May 31, 2001, 20.00 GMT
Note: This web page contains all the material from Paul & Paola's
experiments, but is in some respects preliminary.
Please do not cite. You can cite the available papers instead.
Acoustically, the English vowels /I/ and /i/ differ in vowel height (first formant)
and length (duration). One would expect, therefore,
that listeners rely on both cues when distinguishing between these vowels.
Escudero (to appear b), however,
found that Standard Scottish English listeners rely almost exclusively on height,
while Southern English speakers rely on both durational and spectral cues.
Also, Escudero (to appear a) found that
Spanish speakers of English were divided into four groups: no perceptual distinction
between the two vowels (S0), an exclusive reliance on length (S1),
a reliance on both length and height (S2),
and an almost exclusive reliance on height (S3).
Escudero hypothesised that these perceptual variations are caused by regional variation in production.
In a production experiment, we found that in Scottish English,
/i/ is much shorter than in Southern English,
so that the actually produced durations of /I/ and /i/ overlap appreciably.
Conversely, Southern English /I/ turned out to be much higher than Scottish English /I/,
i.e. spectrally closer to /i/.
To minimize the probability of miscomprehending the speaker's utterance,
the Scottish listener must learn to rely mainly on height,
while the Southern English listener must learn to rely on both length and height.
Our hypothesis, then, is that optimal cue reliance depends on cue reliability.
Boersma's (1998) three-grammar model of phonological acquisition,
which implements a separate perception grammar within an Optimality-Theoretic framework,
predicts exactly this hypothesised relation when a general Gradual Learning Algorithm
(Boersma & Hayes 2001) is applied to the perception grammar (Boersma 1997).
This grammar consists of a large number of constraints such as "an F1 of 350 Hz is not an /I/"
and "a duration of 80 ms is not an /i/", for every value of F1 and duration, and for both vowels.
Thus, if both the spectral and durational continua are divided into 100 discrete regions,
the grammar contains 400 constraints.
We let this algorithm simulate the behaviour of two virtual babies,
little Elspeth and little Liz, who are brought up in Scotland and Southern England,
respectively. We will show how both of these listeners start with the same perception grammar,
in which the constraints are ranked at the same level.
The learners then repeatedly "hear" words with /I/ and /i/,
appropriately distributed with respect to height and length according to their language environment.
Every time little Elspeth or little Liz miscomprehends a word,
she reranks some constraints in her perception grammar.
Gradually, Elspeth comes to rely almost exclusively on height,
whereas Liz comes to rely on both duration and height,
thus achieving adult-like minimisation of perceptual confusion.
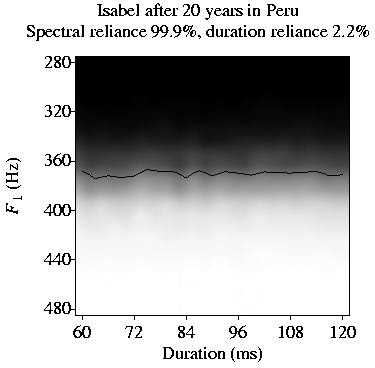
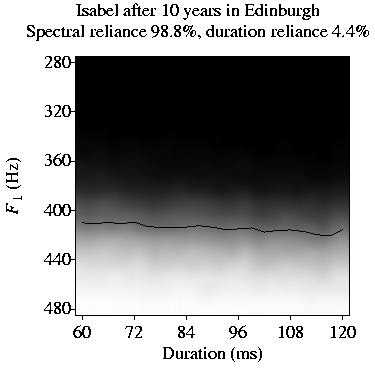
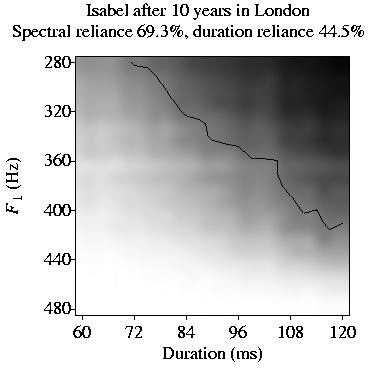
We also let the algorithm simulate the behaviour of two adult Spanish speakers, Isabel and Carmen,
who move to Scotland and Southern England, respectively.
We will show how these simulated listeners start with a copy of their
Spanish perception grammar, in which the height and length reliances are zero
since Spanish has no [I]-[i]-like height contrast and no length contrast (S0).
With time, Isabel comes to rely on height almost exclusively (S3),
whereas Carmen comes to rely on both length and height (S1, S2).
The results show that a listener with an established perception grammar
will also rerank the constraints and can ultimately attain native-like perception.
Finally, we let the algorithm simulate the behaviour of a virtual Spanish speaker
who goes to live in Southern England and later moves to Scotland.
In the South, she gradually comes to rely on both length and height (S1, S2)
and achieves native-like comprehension. This comprehension deteriorates when
she is subsequently exposed to Scottish English.
With time, however, she comes to rely almost exclusively on height (S3)
and returns to proficient comprehension.
Consequently, the formal three-grammar model of Functional Phonology,
together with the Gradual Learning Algorithm,
accounts for the acquisition of an effective perception of sound contrasts.
including the four attested,
possibly sequential, patterns or stages in the weighting of acoustic cues
in L2 phonological acquisition.
The following is meant to be an exhaustive summary of the literature
on the weighting of acoustic cues in phonological categorisation.
We will consider only cases in which at least two cues were varied,
i.e., we will ignore all the studies that show that if all cues except one
are neutralised, the listeners will show a category boundary
when the single remaining cue is varied; these studies only show
that the weighting of that single cue is greater than zero.
Imagine two sounds that differ in two ways acoustically, such as /I/
and /i:/, which differ in height and length. If we plot length
(increasing duration) along the horizontal axis, and height (decreasing F1)
along the vertical axis, we get four stimuli that can determine
which of the cues is primary:
[i] [i:]
[I] [I:]
The stimuli in the bottom left and top right corners are the prototypes for /I/ and /i:/,
respectively. The stimuli in the top left and bottom right corners have crossed acoustic cues.
If in a forced-choice experiment [i] is perceived as /i:/, and [I:] as /I/,
then we say that the spectral (height) cue is primary;
if [i] is perceived as /I/, and [I:] as /i:/, then the duration (length) cue is primary.
Note that we cannot determine in this way whether the other cue is secondary or whether
it is not used at all (that has to be decided by a single-cue experiment,
probably with neutralisation of all the other cues).
This method is suitable in many cases, especially if the synthesis method is restricted
to cutting and pasting.
For the place contrast in English initial plosives,
Schatz (1954) crossed the burst parts and the CV transitions,
and found that xx xx xx.
For the place contrast in English initial fricatives,
Harris (1958) crossed the noise parts and the CV transitions,
and found that the noise was the primary cue except
in the /f/-// comparison,
in which the CV transition was primary.
For the voicing contrast in English final fricatives,
Denes (1955) found that vowel duration outweighed fricative voicing,
i.e. [ju::s] and [ju:z] were recognized as /ju:z/ 'use-V' and /ju:s/ 'use-N', respectively,
if a third cue (consonant duration) was neutralised.
For the voicing contrast in English final plosives,
Eilers, Oller, Urbano & Moroff (1989) found that
the combined cues of vowel duration and periodicity burst (?)
led to better discrimination than either cue alone.
If the possibilities of resynthesis go further than cut and paste,
it becomes possible to establish the actual weighting of the cues.
If, for instance, we can synthesize duration continuously,
we can measure identification along the top and bottom edges of the [I]-[i:] rectangle:
[i] . . . . . [i:]
[I] . . . . . [I:]
If the durational cue is primary, we will find a category boundary along the top edge and
a category boundary along the bottom edge. The category boundary is defined as the point
at which the fraction of /i:/ responses reached the 50 percent point.
If the spectral cue is secondary but effective,
the boundary points will be at different locations along the two edges:
[i] . | . . . [i:]
[I] . . .|. . [I:]
In this example, the category boundary along the bottom is at 4/7 = 57% (of the duration range),
i.e. 4 of the 7 points lie to the left, 3 to the right of this boundary.
Along the top, it is 2.5/7 = 29% (of the duration range).
The difference (28% of the duration range) can be seen as the reliance on the secondary (spectral) cue,
relative to the reliance on the primary (durational) cue, which we can assume is 100% (of the spectral range!).
If we measure each of the 14 points 10 times (i.e. 140 stimuli per listener),
a listener with a perfectly steep boundary will produce the following numbers of /i:/ responses:
0 0 5 10 10 10 10
0 0 0 0 10 10 10
Another way, now, to compute the spectral reliance is to subtract the average
/i:/ response probability for the bottom edge (30/70) from that for the top edge (45/70),
i.e. (45-30)/70 = 28% (of the duration range). Redundantly, the durational reliance is computed by subtracting
the average /i:/ response probability at the left ((0+0)/20) from that at the right
((10+20)/20), again giving 100% (of the spectral range). If the boundary is not perfect, we can still use this method:
4 6 6 7 9 10 10
1 0 0 6 9 10 9
Rather than trying to find the boundary points by some fancy interpolation,
we can directly compute the reliances from all the values along the top and bottom edges.
The spectral reliance is ((4+6+6+7+9+10+10) - (1+0+0+6+9+10+9)) / 70 = 24% (of the duration range),
and the durational reliance is (10+9-4-1)/20 = 70% (of the spectral range).
The cue reliance ratio is then 70% / 24% = 2.9. This number depends on the sizes of the spectral
and duration ranges. We could make it independent of that by multiplying numerator and denominator
by the ranges, e.g. (70% * 140 Hz) / (24% * 90 ms) = 4.5 Hz / ms,
which is a linear estimate of the slope of the category boundary.
The two-continuum method requires that the continously variable cue is the primary cue.
For the voicing contrast in New York English final plosives and fricatives,
Raphael (1972) found with synthetic stimuli
that the duration of the preceding vowel (which he varied continuously)
was a stronger cue than all of the remaining cues (for plosives: formant cutback;
for fricatives: formant cutback, friction duration, and voice bar) together
[methodological problems:
R. draws conclusions about plosives versus fricatives without controlling for the preceding vowel.
Second, he mentions the //-//
contrast as an exception, not realising that his minimal pair "cash"-"casual"
has a phonemic tense-lax split for his New York listeners].
For plosives, the boundary was 42 ms longer for voiceless cues than for voiced cues.
For fricatives, the difference was 34 ms. If the duration continuum runs
from 150 to 350 ms in 10-ms steps (a range of 210 ms!),
this means a reliance of 38/210 = 18% on the remaining cues,
leading to a cue weighting of 85% for vowel duration, 15% for the remaining cues together.
Some raw data (number of /p/ responses out of a total of 25 for each stimulus,
duration going from 150 to 350 ms in 10-ms steps) were:
From these data, we compute a duration reliance of (24+23-1-0)/25/2 = 92%
and a formant cutback reliance of (1+1-1-1+2+2+1+5+5+13+14+17+14+12+3+4-2+1+1+1+1)/25/21 = 18%,
giving weightings of 84% and 16%, respectively.
Hogan & Rozsypal (1980) used natural stimuli for the voicing contrast
in Canadian (Alberta?) English, digitally shortening and lengthening the vowels.
The duration cue for voicedness was overridden by the other cues for voicelessness
in 21 of the 24 continua, and the duration cue for voicelessness was overridden
by the other cues for voicedness in 15 of the 24 continua. The two-continuum method seems
inappropriate for this result, though they present a factor analysis
that suggests that voice bar duration is the primary cue for plosives.
Wardrip-Fruin (1982) also found that the duration cue was minor
(for speakers//listeners whose "speech was judged by two linguists//a linguist to be
without pronounced regional characteristics"). However,
she decided not to include the release burst in her stimuli, so that
the voiceless stimuli ended in silences, thus effectively removing the
consonant duration cue, and with it the consonant/vowel relative duration cue,
thus artificially diminishing the reliability of the vowel duration cue.
In a forced-choice experiment, there will be a category boundary that divides the rectangle
into two parts.
The reliance on the spectral cue can again be measured as the average probability of perceiving
/i:/ along the top, minus the average probability of perceiving /i:/ along the bottom.
Likewise, duration reliance is the average probability of perceiving /i:/ along the right edge,
minus the average probability of perceiving /i:/ along the left edge.
The advantage of the four-continnum method is that it works even if the listeners
have different primary cues.
This method has been used by Escudero (2000), who found that Scottish
listeners rely for 90 percent on the spectral cue when identifying /I/ and /i:/.
The situation changes if we want to compare cue weighting strategies across languages.
First suppose that we use language-particular rectangles. For instance,
Scottish English /I/ and /i:/ are far apart spectrally, but do not differ much in duration
in some positions; by contrast, Southern English /I/ is higher, while /i:/ is lower
than in Scottish English, and /i:/ is longer than in Scottish English.
In an approximated IPA transcription, the rectangles would be:
One of our objectives is to show that perception depends on language and dialect.
The null hypothesis that we try to reject, then, is that all listeners act in the same way,
e.g., that all of them have equal category locations and cue weightings.
Any listener will have a higher spectral reliance and a lower duration reliance
when tested on the Scottish English rectangle than when tested on the Southern English rectangle.
Thus, if we test Scottish English listeners on the Scottish English rectangle,
and Southern English listeners on the Southern English rectangle,
and we find that Scottish English listeners have a higher spectral
reliance and a lower duration reliance than Southern English listeners,
we have no proof of a difference in perception.
In order to prove that the cue weighting strategies of the groups are different,
we have to test the groups with identical rectangles.
This is what Escudero (2000) did for Spanish learners of English in Scotland:
she tested them on the same rectangle that she had used for the native Scottish listeners.
Unlike the Scots, many Spanish listeners of English turned out to rely mainly on duration.
This proves that perception is language-dependent,
not only with respect to the categories, but also with respect to the weighting of acoustic cues.
In an experiment that compares dialects, the rectangle that we should use
is probably the union of the rectangles of the separate dialects.
Thus, we need the following rectangle when comparing listeners of Scottish English
and Southern English:
This is the rectangle that was used by Escudero (2000, reported below)
for the Scottish and Spanish listeners: the heights were typical of Scottish,
the lengths varied by more than a factor of two, which is more typical of Southern English.
The use of the same rectangle for Southern English listeners
(Escudero to appear b, also reported below)
showed that they rely on durational and spectral cues equally.
If we use the union rectangle for all listeners, it becomes likely
that several stimuli on the edges are actually outside both investigated
categories. For instance, the Scottish /I/ could be perceived by
Southern English listeners as their //, and it becomes uncertain
that they will identify this sound as /I/.
We can prevent this situation by allowing the listeners to respond with the "otherwise" category,
i.e., they would have to choose between /I/, /i:/, and "neither". However, if the entire bottom
row is perceived as "neither", we cannot compute any longer
the spectral cue reliance on the basis of the edges of the rectangle.
Instead, we will have to measure the entire two-dimensional rectangle:
Instead of 24 points, we now measure 49 points,
and are confident of finding an /I/-/i:/ boundary somewhere for every listener.
Finally, the computation of cue weighting now suddenly depends on the sizes of the edges of
the rectangle. It could be possible to normalise it, e.g. base it on a "square",
i.e. a rectangle with sides that represent a factor of two in duration and F1,
or with sides that are six just-noticeable difference long.
The development of cue weighting in first-language acquisition has been observed
in the following cases.
Wardrip-Fruin & Peach (1984) showed that for the voicing distinction in English final plosives,
3-year-olds relied mainly on xx duration, 6-year-olds mainly on the spectral cue (first formant),
and adults relied on both equally.
It has often been suggested that cue reliance depends on the reliability
of the cues in the language environment, but people have also argued against this suggestion.
For the voicing contrast in English final plosives and fricatives,
Raphael (1972:1302) ascribes the low reliance on closure voicing
to the unreliable absence of vocal pulsing in voiceless obstruents
(Lisker, Abramson, Cooper & Schvey 1969: in not much more than 80% of the cases),
and the low reliance on the plosive burst strength to its unreliable presence in American English
(Rositzke 1943). The high reliance on vowel duration can be ascribed
to the high reproducibility of that cue: the duration is 1.5 times
larger before voiced than before voiceless consonants (Peterson & Lehiste 1960);
However, Hogan & Rozsypal (1980) found that this factor was
larger for "lax" (intrinsically short) vowels than for "tense" (intrinsically long)
vowels, although the reliance was higher for the tense vowels.
For this reason, Wardrip-Fruin (1982:187) states that "it seems that the very well-established
regularity of vowel duration differences in production may have effected an unwarranted
confidence in their value for perceptual judgments".
Jusczyk (1997:215): "Information about the properties of sounds to which
infants are exposed and their distribution in the input are likely to be critical
factors in shaping the weighting scheme."
Jean Aitchison (1996[2000]:33) on flower perception by bees:
"The order of importance -- odour, then colour, then shape -- is probably
based on cue reliability."
The perception experiment aimed at measuring the cue weighting in the /I/-/i:/ continuum
for native speakers of English and for Spanish learners of English.
The Scottish and Spanish parts of this experiment were performed by Paola in August 2000 as
a part of her M.Sc. work and reported earlier in Escudero (2000) and
Escudero (to appear a). The Southern English part was performed
by Paola in Edinburgh in December 2000 and January 2001 (reported in
Escudero (to appear b)),
and in Reading in February 2001.
20 L1 speakers of Scottish English, 10 female and 10 male,
who reported to have lived in Edinburgh for most of their lives,
aged between 23 and 35 years.
21 L1 speakers of Southern English, 10 of whom lived in Edinburgh, 11 in Reading.
30 L2 speakers of English (L1 Spanish), 15 female and 15 male,
from various regions within Spain and various countries in South America,
aged between 18 and 58 years, being
middle and upper class students (undergraduate and postgraduate) and employees,
who started their L2 learning after the age of 12,
and were visiting or living in Edinburgh when participating in the study.
The subjects reported no hearing problems and accepted to participate in the study voluntarily.
Two Scottish English speakers produced the vowels /I/ and /i:/ ten times each in isolation.
The average F1 of these naturally produced vowels was 484 Hertz for /I/ and 343 Hertz for /i:/.
The average F2 was 1890 Hertz for /I/ and 2328 Hertz for /i:/.
These values were taken as the edges of the stimulus rectangle,
which consisted of 37 vowels synthesised with the Sensyn version
of the Klatt parameter synthesiser at the Linguistics microlab at the University of Edinburgh:
The six vertical steps were equal on the mel scale,
ranging from 480 to 344 Hz for F1 and from 1893 to 2320 Hz for F2.
The frequency in mels was computed as (1000/log 2) log (f/1000 + 1),
and the inverse (mels to Hertz) was 1000 (10mels/(1000/log 2) - 1).
The seven durations ranged from 83 ms to 176 ms in six equal fractional steps of 1.1335.
Here are the sounds:
The experiment was performed in a soundproof room (the Experiment Room
at the Department of Theoretical and Applied Linguistics of the University of Edinburgh)
using the experiment design program Psyscope, running on a Macintosh computer.
The listeners heard 10 tokens of each of the 37 vowels, in randomised order,
divided into 10 blocks of 37 stimuli, between which they were encouraged
to take breaks.
The experiment was a forced identification test.
The subjects had to decide whether the vowel sound they heard was represented
in the picture of a 'ship'
or the picture of a 'sheep'
by pressing one of the two buttons that had these pictures stuck onto them
(or, if there is no button box, the space bar or the zero on the numeric keypad).
They also had verbal and written instructions and were told to guess if not sure.
They were told to take as much time as they thought convenient to make a decision
and they knew that they would not have the next trial if they did not make a decision.
Before the identification test, all subjects were asked for the names
of the objects on the pictures ('sheep' and 'ship'), in order to to find out
whether they made a difference between the two objects or not.
The experimenter never produced the words for neither of the pictures nor did she tell
them that the words were different. For the L1 group, some of the subjects were not sure of
what the object in the red picture was. They thought it was a 'boat' or a 'yacht', and the
experimenter explained that it was something else until they produced the expected word ('ship').
All L1 subjects and 90% of the L2 subjects produced distinctive words for the two pictures.
The majority of the L2 subjects appeared to produce 'sheep' with a long [i] and 'ship'
with a short one. Likewise, the majority of these subjects, after producing the sounds,
referred to the difference as being one of length ('the long and the short', they said).
Of course, they could have thought that the vowels only differ in terms of length
but still perceived and produced a quality difference.
None of the L1 subjects made a similar judgement.
Matrices like the one above were analysed with the Praat script
listeners/analyse_and_draw.praat.
This script draws a rectangle in the Picture window for one or more listeners.
The file listeners/sheeps13.pdf shows
all the pictures.
The pictures also show the reliances on the durational and spectral cues.
The spectral reliance, for instance, was computed (according to section 2.1.3)
as the sum of the /i:/ scores along the top row minus the sum of the /i:/ scores
along the bottom row, divided by 70. For the "cm" example,
we get ((9+10+10+10+10+10+10) - (1+0+1+1+4+2+4)) / 70 = 80 percent.
The durational reliance is the sum of the /i:/ scores along the right edge
minus the sum of the /i:/ scores along the left edge, divided by 70,
i.e. ((4+6+6+7+9+10+10) - (1+0+0+6+9+10+9)) / 70 = 24 percent.
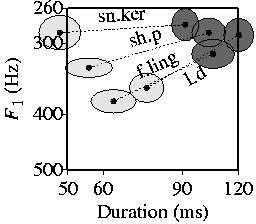
All Scottish listeners except one ("lp") rely almost exclusively on the spectral cue.
One of the pictures shows the results for the Scottish group as a whole.
The average F1 reliance is 93.4%, the average duration reliance 10.6%.
The Southern English listeners rely on both cues.
The average F1 reliance is 65.2%, the average duration reliance 34.6%.
The Spanish listeners can be divided into five groups:
"dmc", "ir", "jr", and "mw" had reversed responses for the prototypical
vowels in this experiment and/or in a parallel experiment that measured
the [I]-[i:] diagonal only. One of the pictures shows the average for
the remaining 26 listeners (spectral reliance 39%, duration reliance 55%).
S0: "cc", "ct", "lchr", "lg", and "mc" did not have a native-like
performance on the [I]-[i:] diagonal. One of the pictures shows the average for
the remaining 21 listeners (spectral reliance 37%, duration reliance 60%).
S1: "ba", "ef", "manl", "mao", "mvl", "of", and "pn" rely on duration only.
Escudero (to appear b) suggests that this group had mainly been exposed to Southern English.
S2: "af", "arg", "fjrg", "jtn", "lj", and "snd" rely primarily on duration,
secondarily on the formant differences.
S3: "abg", "adcg", "al", "jad", "jg", "mcsc", "mf", and "mt"
rely mainly or exclusively on the spectral cue, like the L1 Scottish listeners.
Escudero (2000) suggests that three of these, having been in Scotland
for a very short time, assimilated the Scottish vowels to their native Spanish /e/ and /i/
categories, although they pronounced 'ship' and 'sheep' in the same way (?)
A number of studies have been devoted to the perception of non-native sounds
(see Strange 1995 and Leather & James, to appear).
There is an increasing interest in knowing the way in which L2 perception
works and how different it may be from native perception.
Most of the approaches to L2 perception suggest that the L1 background
has a strong influence in the way the sounds of the target language (TL)
are perceived, at least during the first stages of learning (Ingram and Park 1997).
Two of the most important and influential approaches to L2 vowel perception,
Flege's (1995) Speech Learning Model and Best's (1995) Perceptual Assimilation Model,
explain L2 speakers' behaviour mainly as a function of their previous,
linguistic experience. These two approaches form two different but not
incompatible theoretical models for non-native perception.
We will briefly summarise and discuss some of their claims,
and see how well they can handle the development of cue weighting.
We will then discuss Boersma's (1998) computational model
of perceptual development and compare this with the other two.
This is a mentalist model, in which language-specific sounds
are represented in long-term memory: the resulting representations
that a speaker has of her L1 sounds constitute phonetic categories
(e.g. /s/, /t/, /i/, etc.). The model suggests that TL sounds
that are matched with different L1 sounds will be discriminated
in a native-like fashion. However, there is no guarantee that they
will be fully perceived in the way native speakers perceive them.
The SLM explains the lack of ability to create new categories
for similar sounds on the basis that L2 speakers are not able to
perceive the sub-segmental (non-phonemic) features in which the
L2 and L1 sounds differ: they are perceptually equivalent.
However, the model also suggests that L2 learners may be able to
perceive these non-phonemic features in terms of their experience
with the TL. L2 learners are, in principle, capable of forming new
categories that resemble native-like ones, even for sounds that are
similar to the L1 sounds. In general, this model claims that it is
only the perception of sub-phonemic features that can make L2 speakers
form a new category for the sound and achieve complete native-like perception.
This model assumes that new sounds will get assimilated,
in one way or another, to the categories that already exist in
the speakers' L1. Consequently, the model suggests degrees and
types of assimilation of TL sounds to the L1 perceptual categories
(e.g. they may get assimilated to a single category, two categories, etc).
That is, it provides us with the different ways in which a sound
can be assimilated and the results that this assimilation has for
distinguishing contrastive TL sounds.
The model suggests that L2 speakers have already tuned their
linguistic perceptual device to particular features so they would
have difficulties in detecting the features that the TL sounds
have that are not in their L1. Regarding learnability issues,
the PAM predicts the degrees of discriminability but not the process
involved in the acquisition of such discriminability.
From the two theories above mentioned, it may be inferred that
L2 native-like perception is possible provided L2 speakers
detect the sub-phonemic information or features in the TL sounds
and build up new categories based on them. The models do not mention
that L2 speakers should also detect the relative cue weighting of
the information involved in the TL categories,
neither do they explain what the developmental process for new sounds is.
However, an extension of the models could address cue weighting.
For instance, the PAM would be able to explain how cue weighting
is acquired in terms of a new detection of high level features for the TL.
Likewise, the supporters of the SLM may be able to cope with this
phenomenon by suggesting that the phonetic categories are represented
in long-term memory with their relative, acoustic weighting.
Also, attempts to describe the developmental process of
new contrasts ought to be considered.
In Boersma's (1998) three-grammar model of phonology, categorisation
is handled by a perception grammar, which is implemented as a
stochastic Optimality-Theoretic constraint-ranking grammar.
The model includes a learning algorithm for each of the three grammars.
The perception grammar changes (i.e. reranks its constraints)
as soon as the learner miscategorises an acoustic input.
It seems reasonable to assume that the initial state for
L1 acquisition is an empty perception grammar in which
categorisation constraints are introduced as acoustic input
is processed. It seems also reasonable to assume that the
starting point for L2 acquisition is a copy of the developed perception
grammar of the first language. This assumption of full transfer
has been put forward by Schwartz & Sprouse (1996) and Brown (2000).
Whether we can regard an L2 learner as copying the complete
grammar from her native language (NL) to her interlanguage (IL),
depends on our theory of phonology, namely on whether
it is structuralist, rule-based generative, constraint-based
generative, or functionalist. I will give three examples,
all from Eckman (1981).
From the fact that Spanish learners of English tend to spirantise
postvocalic voiced stops, Eckman concludes that their IL
has a morphophonemic rule of Postvocalic Spirantisation,
neutralising the /d/-// contrast.
The NL, he argues, does not have this morphophonemic rule,
since postvocalic spirantisation is an allophonic rule in Spanish.
Since English obviously does not have Postvocalic Spirantisation
either, the IL has a rule that it does not share with NL and TL.
Hence, no full transfer.
It is clear that this conclusion is based on the structuralist
distinction between morphophonemic and allophonic rules.
Rule-based generative phonology (SPE: Chomsky & Halle 1968)
does not have this distinction, so it would have to conclude
that a rule of Postvocalic Spirantisation is transferred into the IL.
Then Eckman's second example.
From the fact that Spanish learners of English tend to devoice final obstruents,
Eckman argues that their IL has a rule of final devoicing that does not occur
in either their NL or the TL. For a rule of final devoicing to exist in a grammar,
the language has to have an obstruent voice contrast
that is actively neutralised in final position.
For instance, the German medial voice contrast in /ta:g/ 'days'
versus /dk/ 'decks'
is neutralised in /ta:k/ 'day' and /dk/ 'deck'.
Eckman states that in order for there to be a rule,
there should be alternation and neutralisation.
In Spanish, however, there is no alternation, so Spanish does not have a final devoicing rule
[how shall we account for ciudad?].
Since English obviously has no final devoicing either,
we must conclude that only the IL has this rule. Hence, no full transfer.
But this conclusion is based on a theory of ordered rules.
This is like Smith's (1973) account of a child who pronounces
underlying |s| as []: Smith describes
this with a rule /s/ -> //, i.e., the
child has a more complicated grammar than the adult.
Constraint-based generative phonology (Optimality-Theory: Prince & Smolensky 1993), however,
describes surface generalisations as high-ranked markedness constraints.
Any language that does not allow final voiced obstruents has a ranking of
*FINALVOICEDOBSTRUENT
>> IDENT(voice)
(the latter constraint means "any underlying voicing specification is realised in the output").
This ranking has not changed from the child's initial state,
in which all markedness constraints outrank all faithfulness constraints (Smolensky 1996).
The point is that the lexicon need not contain voiced final obstruents:
the maxim of Richness of the Base (Prince & Smolensky 1993:191, Smolensky 1996) ensures
that any underlying final voiced obstruents (even if they do not
exist in the language) are devoiced. Thus, an OT account would state that the ranking
*FINALVOICEDOBSTRUENT
>> IDENT(voice) is transferred into the IL.
Then Eckman's third example.
From the fact that Mandarin speakers of English tend to append
a schwa after final voiced obstruents (tag, rob, is),
Eckman argues that their IL has an optional rule of Schwa Paragoge.
No such rule is needed for Mandarin, which has no underlying final
obstruents, nor, obviously, for English. A generative OT account, with initial high-ranked
*FINALOBSTRUENT,
would predict either dropping of the final obstruent or schwa paragoge,
depending on the ranking of the faithfulness constraints
MAX(obs) ("any underlying obstruent is realised in the output")
and DEP(schwa) ("do not insert a non-underlying schwa").
But according to the initial state hypothesis by Smolensky (1996)
and the learning algorithm by Tesar & Smolensky (1998),
all undominated faithfulness constraints should end up
in the second stratum of the grammar, i.e. be ranked equally high,
presumably with free L2 variation as a result.
The choice for MAX(obs) >> DEP(schwa) in this IL,
therefore, corresponds to nothing in the NL. Hence, no full transfer.
But this conclusion is based on an initial ranking of all markedness
constraints above all faithfulness constraints,
and on an ordinal learning algorithm. In Functional Phonology
(Boersma 1998), however, articulatory constraints are ranked by
articulatory effort, and faithfulness constraints are ranked
by perceptual confusion. While the initial state can be regarded
as a high ranking of articulatory constraints, analogously to
the (seriously flawed...) markedness constraints of generative OT,
the faithfulness constraints are still ranked by whether
it is worse to delete an underlying obstruent or to insert
a non-underlying schwa. The answer depends on the difference
in amount of perceptual confusion that these deletions and
insertions would cause, and this can be learned if the NL language
environment is not perfect, as it never is, provided that
we understand that a gradual learning algorithm is needed;
it can also be learned rather swiftly during L2 contact,
if, given the high ranking of *FINALOBSTRUENT,
speakers notice more confusions when deleting the obstruent
than when appending a schwa, which seems plausible.
(consult Silverman 1992 and Broselow et al. 1998;
also Steriade 2000 and others, who
state that this vowel epenthesis can never happen)
A paper that explicitly states that hidden rankings are transferred
from L1 to L2 is Smolensky, Davidson & Jusczyk (2000).
We see that the four theories of phonology have different
opinions on whether a certain phenomenon is transferred or not.
The following table summarises the results, with plus signs
where the theory in question proposes transfer:
Apparently, Functional Phonology is the only of the four theories
that can regard all three rules as being transferred into the interlanguage.
Thereby, it is the only of the four theories that can account for
the behaviour of these L2 speakers without invoking extralinguistic
explanations like those that Eckman provides. Eckman antipicated
OT by invoking a "surface phonetic constraint" against final obstruents,
the "maintenance of a canonical form of the intended TL word"
(faithfulness), and "conflict resolution". He also
anticipated functionalist OT with his "markedness differential
hypothesis", which prohibits voicing more in final than in other
positions.
Since the theory of Functional Phonology turns out to be able to formalise
many factors that used to be considered extralinguistic,
we will hypothesise that the L2 learner's initial IL perception grammar
is an identical copy of her NL perception grammar.
Until the facts prove us wrong!
Kirchner (to appear) published the following criticism on Boersma's
perception grammar, originally vented by Terry Nearey (p.c., 1999):
"Boersma's discussion is the first to spell
out a constraint system with sufficient power to
deal plausibly with raw numeric representations.
It would have been helpful, however, if Boersma had
gone beyond this unidimensional F1 frequency case,
to provide some discussion of how values from
multiple auditory dimensions can be integrated,
within this formalism, to yield complex perceptual
categories such as place of articulation, or voicing".
Exactly this is what the current project aims at accomplishing.
Chapter 15 of Boersma (1998) contained a simulation of a one-dimensional continuum
(simulation/categ1_learning.praat.txt).
The basic idea is that for e.g. vowel height, the perceived category is determined
on the basis of the ranking of constraints against mapping F1 values to each category,
such as "350 Hz is not /i/", "350 Hz is not /e/", "350 Hz is not /a/",
"370 Hz is not /i/", "370 Hz is not /e/", "370 Hz is not /a/", and so on for all F1 values
and all categories.
There are two ways to extend the 1-dimensional model. The first is a high-level integration of cues.
For the /I/-/i:/ contrast, this would mean that the listener first classifies F1 and duration
into discrete height and length categories, then decides which is more important if the
two are in conflict. The first step (cue categorization) would, for instance, map
a certain first formant f to [+high] with the probability P (+high | F1=f),
and a certain duration d to [+long] with the probability P (+long | duration=d).
The second step (integration of binary cue values) would then be handled by constraints like
"[+high] is not /I/", "[-high] is not /i:/", "[+long] is not /I/", and "[-long] is not /i:/".
Suppose that these conflict, i.e. the cues have been constructed as [+high] and [-long],
so that the result has to be determined by the relative ranking of the two constraints
"[+high] is not /I/" and "[-long] is not /i:/". Saying that duration is the primary cue,
is the same as saying that "[-long] is not /i:/" is ranked above "[+high] is not /I/".
If the ranking difference is not large, then "[+high] is not /I/" may still outrank
"[-long] is not /i:/" in a minority of cases, say 20% of the perceptions.
The probability of an /i:/ response is then P (/i:/ | F1=f, duration=d) =
20% x P (+high | F1=f) + 80% x P (+long | duration=d).
This causes the identification curve for the top row (the [i]-[i:] continuum)
to lie exactly 20% above the identification curve for the bottom row (the [I]-[I:] continuum):
100% /i:/ * * * * * [i:]
| * *
| * o o o o o [I:]
| * o o
| * o
| * o
| * * o
| [i] * * * * * o
| o o
0% /i:/ [I] o o o o o duration ->
Thus, the difference between the two curves is always 20%, giving a spectral reliance of 20%.
However, the actual curves do not look like this. The /b/-/p/ curves discussed in section
2.1.2 do not seem to be vertically, but horizontally shifted:
100% /b/ * * * * * o o o o o
| * * o o
| * o
| * o
| * o
| without F1 cutback * o with F1 cutback
| * o
| * o
| * o
| * * o o
0% /b/ * * * * * o o o o o vowel duration ->
This suggests low-level cue integration. It corresponds to a straight boundary in the
two-dimensional continuum, as if the criterium for deciding between /I/ and /i:/
is a function of a linear combination of F1 and duration values. In other words,
the probability of an /i:/ response is P (/i:/ | F1=f, duration=d) =
P (/i:/ | 20% x F1 + 80% x duration = x).
For our simulations, we simply use separate constraint families for the height and length
continua, i.e. constraints like "350 Hz is not /i:/" and "80 ms is not /I/",
for many values of F1 and duration.
This experiment is reported in Escudero & Boersma (2001).
To get the distributions of duration and F1 of /I/ and /i:/
of speakers of various dialects, we recorded (November 2000, Reading)
fifty tokens of each of the words
ship, sheep, filling, feeling,
Snicker, sneaker, lid, and lead
in the carrier sentence THIS is a __ as well.
This sentence was chosen in order that the speakers would destress the target words.
There were also ten distractor words, which were recorded ten times each:
car, bicycle, chair, kitchen, pad,
lip, speaker, mailing, warning, and table.
In total, every speaker pronounced 500 sentences, which took them about 30 minutes.
The words were put in a semi-random order, with every decade
containing each of the eight target words. For instance, the first four words
were lead, Snicker, ship, and feeling,
i.e. they were taken from the four different pairs, in randomised order
and with a random choice between /I/ and /i:/. Words 6 through 9
were their complements, again in randomised order: sneaker,
lid, sheep, and filling. Words 5 and 10 were
the fillers car and bicycle, taken cyclically from
the above distractor list. The complete word list is
speakers/stimuli_20001121.txt. This list was generated once with
the Praat script speakers/order.praat.
The subject would sit at a table with a microphone, and the
carrier phrase was stuck to this table. The words were written on 500 cards
by the Praat script speakers/draw_cards.praat.
The subject was first asked to say two sets of ten sentences,
in order to see if he understood the task. Still, several subjects
could not learn to destress the target words.
The subject was then asked to handle five decks of 50 cards each,
and after a break he was asked to handle the remaining five decks.
The experimenter was sitting beside the subject with a copy
of the word list (speakers/stimuli.doc),
on which s/he could mark any hesitations. If the subject hesitated
at any words, these words were recorded again after the experiment.
For each speaker, the sound file was labelled by both of us with the help of the Praat
program (January 2001, Reading). The sound file is opened with Open long sound file...,
and an empty TextGrid with one tier is created from the resulting LongSound.
The word list is read into Praat
with Create Strings from raw text file.... The TextGrid and Strings
objects are selected together, and the Praat script
speakers/initTextGrid.praat
creates 500 intervals of 1 second duration, dispersed evenly throughout
the TextGrid (the times of the first and 500th words can be given to the script).
The intervals are labelled 1 lead, 2 Snicker, and so on.
Paul then selects LongSound plus TextGrid, clicks View,
and shifts the 1000 boundaries so that they confine the target words;
this takes about 100 minutes. The resulting TextGrid files are:
After these preparations, both Paul and Paola take the TextGrid file
and move the boundaries in such a way that they confine the vowel /I/ or /i:/
(select TextGrid plus LongSound, then choose Edit).
Procedure:
Do Find or "Find again" to find the next occurrence of the word, e.g. "ship".
Listen to the word and identify the location of the vowel, and move the boundaries
approximately to the beginning and end of the vowel.
Click in the word interval. The selection will snap to the approximation of the vowel.
Click "sel" to zoom in to the selection, then "out".
Move the approximate boundaries to accurate positions based on wave form
and spectrogram (Praat version 3.9.12 or higher).
Move boundaries inward to zero crossings (zoom in as needed).
A sibilant-vowel boundary, however,
is determined as the first zero crossing after the noise has stopped.
The criteria for setting boundaries on the basis of the spectrogram:
/Vp/, /Vd/, and /Vk/: "energy in the region of F2 and the higher formants
ceases to be visible on the spectrogram display."
(Hieronymus et al. 1990).
The results were put together in TextGrids with two tiers, which were then edited
for consistency across words and across annotators (February 2001, Amsterdam).
The preliminary versions are:
The mean F1 and F2 of each vowel (measures of vowel quality).
These quantities were measured for each speaker from LongSound + TextGrid, with the script
speakers/measureVowels.praat,
which puts the result into a TableOfReal object. The two TableOfReal objects were
merged (with "Append"), giving speakers/all.TableOfReal,
which can be read (after minimal editing) into Excel or SPSS for e.g. factor analysis
(i.e. duration/F1/F2 as functions of region, vowel category, number of syllables,
and voicing of the following consonant).
However, we did the following basic statistics with the Praat script
speakers/statistics.praat.
The resulting (geometric) average duration/F1/F2 values were for the Scottish English speaker (in ms/Hz/Hz):
mean
s.d.
mean
s.d.
mean
s.d.
mean
s.d.
ship
90.7 480 1752
0.183 0.038 0.036
lid
134.0 480 1726
0.182 0.051 0.047
filling
76.8 492 1647
0.096 0.054 0.056
Snicker
55.5 489 1774
0.151 0.098 0.040
sheep
92.0 327 2282
0.143 0.067 0.030
lead
162.2 324 2345
0.184 0.064 0.024
feeling
93.1 346 2113
0.095 0.034 0.035
sneaker
56.2 378 2302
0.194 0.059 0.041
The standard deviations are expressed in duration doublings and octaves.
For the Southern English speaker, the table is:
mean
s.d.
mean
s.d.
mean
s.d.
mean
s.d.
ship
55.7 331 1683
0.176 0.057 0.032
lid
75.0 359 1683
0.128 0.086 0.038
filling
63.2 379 1528
0.168 0.069 0.038
Snicker
48.0 287 1732
0.155 0.101 0.047
sheep
103.1 287 1951
0.125 0.085 0.050
lead
120.3 290 2099
0.111 0.098 0.070
feeling
105.4 313 1938
0.159 0.086 0.064
sneaker
91.4 278 2010
0.101 0.095 0.062
In all cases, the number of replications was N=50,
except in the case of Scottish "feeling" and Southern "sheep", where N=49.
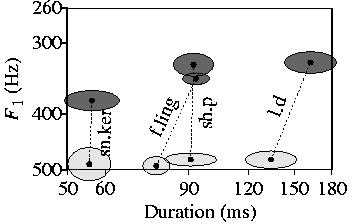
The following picture shows the averages of the Scottish English words
(script speakers/drawScottish.praat);
dark ellipses are /i/, light ellipses are /I/:
As far as the Scottish speaker is concerned, his height distinction
(5 to 11 standard deviations) is much more reliable than his length distinction
(0 to 2.5 standard deviations), whereas the Southern speaker's height distinction
(0.5 to 3 standard deviations) is much less reliable than his length distinction
(4 to 7 standard deviations).
Conversely, we see that the Scottish speaker uses duration for, in order of importance:
the number of syllables (by a factor of 1.6 to 1.8)
the voicing of the following consonant (1.4 to 1.8)
the vowel category (1.0 to 1.2)
whereas the Southern English speaker uses duration for:
the vowel category (1.6 to 1.9)
the voicing of the following consonant (1.2 to 1.3)
the number of syllables (1.1 to 1.2)
From both viewpoints, we can see that duration is a minor cue to the vowel category
in Scottish English production. The regional variation in production thus correlates with
the regional variation in perception.
Here are the averages:
Scottish
mean
s.d.
Southern
mean
s.d.
/I/
84.8 ms 485 Hz
0.485 dbl 0.066 oct
/I/
59.7 ms 337 Hz
0.284 dbl 0.170 oct
/i/
94.0 ms 343 Hz
0.565 dbl 0.105 oct
/i/
104.6 ms 292 Hz
0.188 dbl 0.110 oct
The mean values in this table are geometrically averaged across consonantal context (i.e.
whether the following consonant is voiced or voiceless) and across number
of syllables (1 or 2). The total standard deviations in this table include the within-context variation
and the between-context variation.
This stuff was reported in Escudero & Boersma (2001).
In the first simulation, we model the perceptual development of virtual Elspeth and virtual Liz,
who grow up in a Scottish English and Southern English environment, respectively.
With the script
simulation/createInitialGrammar.praat,
we created an initial perception grammar simulation/baby.OTGrammar,
with 84 constraints like "330 Hz is not /I/" and "90 ms is not /i/".
There were 21 F1 values, varying from 280 to 480 Hz in logarithmically equal steps,
and 21 duration values, varying from 60 to 120 ms in logarithmically equal steps.
In the baby's grammar, all these constraints were ranked at the same height.
We measured the output distribution of this baby by confronting her with 1000
instances of each of the 441 F1-duration pairs,
with the script simulation/measureListener.praat,
which records her number of /i/ responses
into the Praat matrix simulation/baby.Matrix.
This perception matrix is drawn with the script
simulation/drawCategorization.praat,
which produces the following picture:
This picture paints F1-duration pairs that are mainly perceived as /i/ in black,
and those that are mainly perceived as /I/ in white. The entire picture is grey, though,
meaning that every F1-duration pair is perceived as /i/ approximately 50 percent
of the time. The black contours depict the 50% category boundaries.
We see that the baby's reliance on both spectrum and duration is below one percent (as measured with
simulation/computeReliances.praat).
To have our two virtual listeners learn L1 English, we confronted them
with acoustic environments (duration and F1) based on the production distribution that we had
measured in the production experiments:
Scottish
mean
s.d.
Southern
mean
s.d.
/I/
84.8 ms 485 Hz
0.40 dbl 0.20 oct
/I/
59.7 ms 337 Hz
0.40 dbl 0.20 oct
/i/
94.0 ms 343 Hz
0.40 dbl 0.20 oct
/i/
104.6 ms 292 Hz
0.40 dbl 0.20 oct
Rather simplifyingly, we will use these averaged values as the vowel prototypes for Elspeth and Liz.
With the script
simulation/createEnvironment.praat,
we created the Scottish English input-output distribution
simulation/scot.PairDistribution
and the Southern English input-output distribution
simulation/seng.PairDistribution,
representing the probability of occurrence of each of the 441 F1-duration values
for /i/ and /I/ in the environment of the learner.
The distributions were centred about the above mean F1 and duration values
for the Scottish and Southern English speakers, and had standard deviations of
0.20 octaves and 0.40 duration doublings, as in the table.
These standard deviations are different from those derived from the production experiment,
since we can expect our listeners to partly normalize away
the variation due to the consonant environment and the number of syllables
(which would decrease the standard deviations),
but there is also variation not taken into account in the production experiment
(speaking rate, stress, vocal tract size).
These standard deviations are the main unknown factor in our simulation,
and influence the resulting cue reliances rather heavily.
In Praat, OT learning is simulated by selecting an OTGrammar and a PairDistribution
object, then choosing Learn.... For Elspeth and Liz, we used the script
simulation/simulations.praat.
After 1, 2, 4, 10, 100, and 1000 months we measured the resulting grammars,
again with the script
simulation/measureListener.praat.
For Elspeth, the perceptual development is seen in the following matrices:
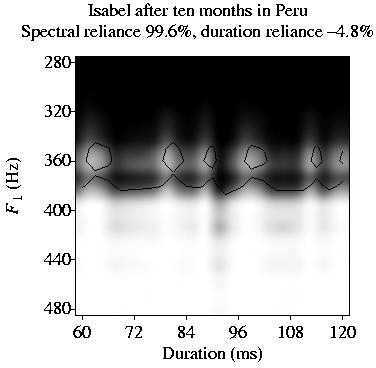
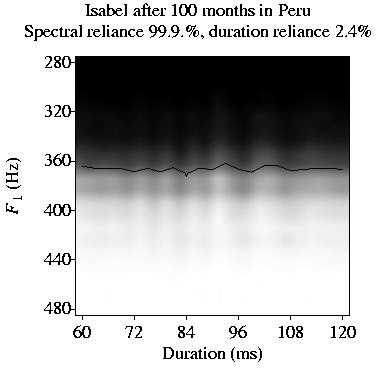
Isabel has become a fluent listener of Spanish. She then goes to Edinburgh and copies her L1 grammar
(all the constraints and their rankings) to the grammar of her interlanguage (full transfer).
She will identify Scottish English /i/ with her existing /i/, and Southern English /I/ with her
existing /e/ (two-category assimilation). After 100 months, she is a fluent listener of Scottish English:
She has become a native-like listener of Southern English.
Real Spanish learners of English often act differently: Spanish learners of Scottish English
tend to rely on spectrum only, and Spanish learners of Southern English tend to rely on duration only.
Apparently, these learners have a different constraint set, with thing like
"350 is not /high/", "350 is not /mid/", "80 ms is not /short/", "80 ms is not /long/",
i.e. they do not integrate the cues to segments but they classify each continuum separately.
This suggests that native speakers of English have separate /I/ and /i/ symbols,
whereas Spanish learners of English have /mid,front/ and /high,front/ (in Scotland)
or /high,short/ and /high,long/ (in Southern England).
Boersma, Paul (1998):
Functional Phonology. Doctoral thesis, University of Amsterdam.
The Hague: Holland Academic Graphics.
Boersma, Paul &
Bruce Hayes (2001):
Empirical tests of the Gradual Learning Algorithm.
Linguistic Inquiry 32: 45-86.
Bohn, Ocke-Sven (1995):
Cross language speech perception in adults first language transfer doesn't tell it all.
In Strange (ed.), 279-304.
Broselow, Ellen &... (1998):
SSLA
Brown, Cynthia (2000):
The interrelation between speech perception and phonological acquisition
from infant to adult.
In John Archibald (ed.) Second language acquisition and linguistic theory.
Malden, Mass. & Oxford: Blackwell. 4-63.
Chomsky, Noam &
Morris Halle (1968):
The sound pattern of English.
New York: Harper and Row.
Denes, Paul (1955):
Effect of duration on the perception of voicing.
Journal of the Acoustical Society of America 27: 761-764.
Di Simoni, F.G. (1974):
Influence of consonant environment on duration of vowels in the speech of
three-, six-, and nine-year-old children.
Journal of the Acoustical Society of America 55: 362-363.
Eckman, Fred R. (1981):
On the naturalness of interlanguage phonological rules.
Language Learning 31: 195-216.
Eilers, Rebecca, D.K. Oller, Richard Urbano & Debra Moroff (1989):
Conflicting and cooperating cues: perception of cues to final
consonant voicing by infants and adults.
Journal of Speech and Hearing Research 32: 307-316.
Flege, James Emil (1995):
Second language speech theory, findings and problems.
In Strange (ed.), 233-277.
Flege, James E., Ocke-Sven Bohn & S. Jang (1997):
Effects of experience on non-native speakers' production and perception of English vowels.
Journal of Phonetics 25: 437-470.
Fox, R.A., James E. Flege & M.J. Munro (1995):
The perception of English and Spanish vowels by native English and Spanish listeners:
A multidimensional scaling analysis.
Journal of the Acoustical Society of America 97: 2540-2550.
Gerrits, Ellen (2001):
The categorisation of speech sounds by adults and children.
Ph.D. dissertation, University of Utrecht. ISBN 90-76912-08-4.
Greenlee, M.E. (1978):
Learning the phonetic cues to the voiced/voiceless distinction:
an exploration of parallel processing in phonological change.
Ph.D. dissertation, University of California at Berkeley.
Hieronymus, J., M. Alexander, C. Bennett, I. Cohen, D. Davies, J. Dalby,
J. Laver, W. Barry, A. Fourcin & J. Wells (1990):
Proposed speech segmentation criteria for the SCRIBE project.
Centre for Speech Technology Research, University of Edinburgh, and
Department of Phonetics and Linguistics, University College London.
Guion, Susan,
James E. Flege, R. Akahane-Yamada & J. Pruitt (2000):
An investigation of current models of second language speech perception:
The case of Japanese adults' perception of English consonants.
Journal of the Acoustical Society of America 107: 2711-2724.
Guion, Susan,
James E. Flege & J. Loftin (2000):
The effect of L1 use on pronunciation in Quichua-Spanish bilinguals.
Journal of Phonetics.
Harris, Katherine S. (1958):
Cues for the discrimination of merican English fricatives in spoken syllables.
Language and Speech 1: 1-7.
Hogan, John T. & Anton J. Rozsypal (1980):
Evaluation of vowel duration as a cue for the voicing distinction
in the following word-final consonant.
Journal of the Acoustical Society of America 67: 1764-1771.
House, A.S. (1961):
On vowel duration in English.
Journal of the Acoustical Society of America 33: 1174-1178.
House, A.S. & G. Fairbanks (1953):
The influence of consonant environment upon the secondary
acoustical characteristics of vowels.
Journal of the Acoustical Society of America 25: 105-113.
Ingram, J.C.L. & S.G. Park (1997):
Cross-language vowel perception and production by Japanese and Korean learners of English.
Journal of Phonetics 25: 343-370.
Jusczyk, Peter (1997):
The discovery of spoken language.Cambridge, Mass.: MIT Press.
Kirchner, Robert (to appear):
Review of Boersma's (1998) dissertation.
GLOT International 49 (9/10): 14-15.
Klatt, Dennis H. (1973):
Interaction between two factors that influence vowel duration.
Journal of the Acoustical Society of America 54: 1102-1104.
Klatt, Dennis H. (1976):
Linguistic uses of segmental duration in English: Acoustic and perceptual evidence.
Journal of the Acoustical Society of America 59: 1208-1221.
Krause, S.E. (1978):
Developmental use of vowel duration as a cue to postvocalic consonant voicing:
a perception and production study. Ph.D. dissertation, Northwestern University,
Evanston, Illinois.
Krause, S.E. (1982):
Vowel duration as a perceptual cue to postvocalic consonant voicing in young children and adults.
Journal of the Acoustical Society of America 71: 990-995.
Leather, Jonathan & Allan James (eds., to appear):
Proceedings of the 4th International Symposium on the Acquisition
of Second-Language Speech, New Sounds 2000, University of Amsterdam.
Liberman, Alvin M., Paul C. Delattre & Franklin S. Cooper (1958):
Some cues for the distinction between voiced and voiceless stops
in initial position. Language and Speech 1: 153-167.
Lisker, Leigh, Arthur S. Abramson, Franklin S. Cooper & Malcolm H. Schvey (1969):
Transillumination of the larynx in running speech.
Journal of the Acoustical Society of America 45: 1544-1546.
Malécot, A. (1970):
The lenis-fortis opposition: its physiological parameters.
Journal of the Acoustical Society of America 47: 1588-1592.
Mermelstein, Paul (1978):
On the relationship between vowel and consonant identification
when cued by the same acoustic information.
Perception and Psychophysics 23: 331-336.
Naeser, M.A. (1970):
The American child's acquisition of differential vowel duration.
Ph.D. dissertation, University of Wisconsin.
Nearey, Terrance M. (1989):
Static, dynamic and relational properties in vowel perception.
Journal of the Acoustical Society of America 85: 2088-2113.
Nittrouer, Susan (2000):
Learning to apprehend phonetic structure from the speech signal: the hows and whys.
Paper presented at the VIIIth Meeting of
the International Clinical Phonetics and Linguistics Association, Queen
Margaret University College, Edinburgh.
Nittrouer, Susan, Chris Manning & G. Meyer (1993):
The perceptual weighting of acoustic cues changes with linguistic experience.
Journal of the Acoustical Society of America 94: 1865.
Parker, E.M., Randy L. Diehl & K.R. Kluender (1986):
Trading relations in speech and nonspeech.
Perception and Psychophysics 39: 129-142.
Peterson, Gordon E. & Ilse Lehiste (1960):
Duration of syllable nuclei in English.
Journal of the Acoustical Society of America 32: 693-703.
Polka, Linda (1995):
Linguistic influence in adult perception of non-native vowel contrasts.
Journal of the Acoustical Society of America 97: 1286-1296.
Polka, Linda & Janet F. Werker (1994):
Developmental changes in the perception of nonnative vowel contrasts.
Journal of Experimental Psychology: Human Perception and Performance 20: 421-435.
Prince, Alan &
Paul Smolensky (1993):
Optimality Theory: Constraint interaction in generative grammar.
Technical Report TR-2, Rutgers University Center for Cognitive Science.
Raphael, Lawrence J. (1972):
Preceding vowel duration as a cue to the perception of the voicing characteristic
of word-final consonants in American English.
Journal of the Acoustical Society of America 51: 1296-1303.
Repp, Bruno H. (1982):
Phonetic trading relations and context effects. New evidence for a phonetic mode of perception.
Psychological Bulletin 92: 81-110.
Revoile, S., J.M. Pickett, L.D. Holden & David Talkin (1982):
Acoustic cues to final stop voicing for impaired- and normal-hearing listeners.
Journal of the Acoustical Society of America 72: 1145-1154.
Rositzke, H. (1943):
xx.
American Speech 18: 39-42.
Schatz, C.D. (1954):
The rôle of context in the perception of stops.
Language 30: 47-56.
Schwartz, Bonnie & Rex Sprouse (1996):
L2 cognitive states and the Full Transfer/Full Access model.
Second Language Research 12: 40-72.
Scobbie, Jim (1998):
Interactions between the acquisition of phonetics and phonology.
In K. Gruber, D. Higgins, K. Olsen & T. Wysochi (eds.)
Papers from the 34th Annual Meeting of the Chicago Linguistic Society II.
Chicago: Chicago Linguistic Society. xx-xx.
Silverman, Daniel (1992):
xx
Phonology
Smith, B.L. (1978):
Temporal aspects of English speech production: a developmental perspective.
Journal of Phonetics 6: 37-67.
Smith, Neilson V. (1973):
The acquisition of phonology: A case study.
Cambridge: Cambridge University Press.
Smolensky, Paul (1996):
The initial state and 'richness of the base' in Optimality Theory.
Technical Report 96-4, Department of Cognitive Science, Johns Hopkins University, Baltimore.
Rutgers Optimality Archive 154.
Steriade, Donca (2000):
xx
Talk presented at the First North American Phonology Conference, Montreal.
Strange, Winifred (ed., 1995):
Speech perception and linguistic experience:
Theoretical and methodological issues. Baltimore: York Press.
Strange, Winifred, T.R. Edman & J.J. Jenkins (1979):
Acoustic and phonological factors in vowel identification.
Journal of Experimental Psychology: Human Perception and Performance 5: 643-656.
Tesar, Bruce &
Paul Smolensky (1998):
Learnability in Optimality Theory.
Linguistic Inquiry 29: 229-268.
Wang, W. S.-Y. (1959):
Transition and release as perceptual cues for final plosives.
Journal of Speech and Hearing Research 2: 66-73.
Wardrip-Fruin, Carolyn (1980):
On the status of temporal cues to phonetic categories: Preceding vowel duration
as a cue to voicing in final stops. Ph.D. dissertation, Stanford University, California.
Wardrip-Fruin, Carolyn (1982):
On the status of temporal cues to phonetic categories: Preceding vowel duration
as a cue to voicing in final stop consonants.
Journal of the Acoustical Society of America 71: 187-195.
Wardrip-Fruin, Carolyn & S. Peach (1984):
Developmental aspects of the perception of acoustic cues
in determining the voicing feature of final stop consonants.
Language and Speech 27: 367-379.
Zimmerman, S.A. & S.M. Sapon (1958):
Note on vowel duration seen cross-linguistically.
Journal of the Acoustical Society of America 30: 152-153.
 / comparison,
in which the CV transition was primary.
For the voicing contrast in English final fricatives,
Denes (1955) found that vowel duration outweighed fricative voicing,
i.e. [ju::s] and [ju:z] were recognized as /ju:z/ 'use-V' and /ju:s/ 'use-N', respectively,
if a third cue (consonant duration) was neutralised.
For the voicing contrast in English final plosives,
Eilers, Oller, Urbano & Moroff (1989) found that
the combined cues of vowel duration and periodicity burst (?)
led to better discrimination than either cue alone.
/ comparison,
in which the CV transition was primary.
For the voicing contrast in English final fricatives,
Denes (1955) found that vowel duration outweighed fricative voicing,
i.e. [ju::s] and [ju:z] were recognized as /ju:z/ 'use-V' and /ju:s/ 'use-N', respectively,
if a third cue (consonant duration) was neutralised.
For the voicing contrast in English final plosives,
Eilers, Oller, Urbano & Moroff (1989) found that
the combined cues of vowel duration and periodicity burst (?)
led to better discrimination than either cue alone.
 /-/
/-/ /
contrast as an exception, not realising that his minimal pair "cash"-"casual"
has a phonemic tense-lax split for his New York listeners].
For plosives, the boundary was 42 ms longer for voiceless cues than for voiced cues.
For fricatives, the difference was 34 ms. If the duration continuum runs
from 150 to 350 ms in 10-ms steps (a range of 210 ms!),
this means a reliance of 38/210 = 18% on the remaining cues,
leading to a cue weighting of 85% for vowel duration, 15% for the remaining cues together.
Some raw data (number of /p/ responses out of a total of 25 for each stimulus,
duration going from 150 to 350 ms in 10-ms steps) were:
/
contrast as an exception, not realising that his minimal pair "cash"-"casual"
has a phonemic tense-lax split for his New York listeners].
For plosives, the boundary was 42 ms longer for voiceless cues than for voiced cues.
For fricatives, the difference was 34 ms. If the duration continuum runs
from 150 to 350 ms in 10-ms steps (a range of 210 ms!),
this means a reliance of 38/210 = 18% on the remaining cues,
leading to a cue weighting of 85% for vowel duration, 15% for the remaining cues together.
Some raw data (number of /p/ responses out of a total of 25 for each stimulus,
duration going from 150 to 350 ms in 10-ms steps) were:
 /, and it becomes uncertain
that they will identify this sound as /I/.
We can prevent this situation by allowing the listeners to respond with the "otherwise" category,
i.e., they would have to choose between /I/, /i:/, and "neither". However, if the entire bottom
row is perceived as "neither", we cannot compute any longer
the spectral cue reliance on the basis of the edges of the rectangle.
Instead, we will have to measure the entire two-dimensional rectangle:
/, and it becomes uncertain
that they will identify this sound as /I/.
We can prevent this situation by allowing the listeners to respond with the "otherwise" category,
i.e., they would have to choose between /I/, /i:/, and "neither". However, if the entire bottom
row is perceived as "neither", we cannot compute any longer
the spectral cue reliance on the basis of the edges of the rectangle.
Instead, we will have to measure the entire two-dimensional rectangle:
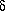 / contrast.
The NL, he argues, does not have this morphophonemic rule,
since postvocalic spirantisation is an allophonic rule in Spanish.
Since English obviously does not have Postvocalic Spirantisation
either, the IL has a rule that it does not share with NL and TL.
Hence, no full transfer.
/ contrast.
The NL, he argues, does not have this morphophonemic rule,
since postvocalic spirantisation is an allophonic rule in Spanish.
Since English obviously does not have Postvocalic Spirantisation
either, the IL has a rule that it does not share with NL and TL.
Hence, no full transfer.