In this study, we present detailed analyses on segmental (phone) durations as influenced by several important contextual factors. First duration distributions for such individual factors are presented. Then an adapted ANOVA is used to study the systematic contributions of the 11 factors under concern. In order to make the analysis results useful for improving ASR performance, the speech database chosen should be somehow close to the real-life situation e.g. it must be continuous speech of many speakers. Yet for analysis purposes it must be fully hand-labelled. That's why we chose the TIMIT database which has been used for many related studies (e.g. [5], [14], [6]). In the present study the data set used contains all 3,696 si and sx utterances (4,891 different words) of the TIMIT training set, spoken by 462 speakers (326 male/136 female).
2. Phone duration distributions
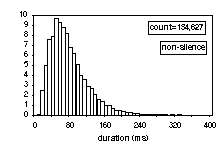
- 1. The hand-labelled sequence with 142,910 segments, of which 8,283 are long pauses, leaving 134,627 real phone (and closure) segments;
- 2. The lexical form, representing the ideal or norm pronunciation of each word in isolation. Stringing these word pronunciations together to form utterance pronunciations, produces a larger number of segments (154,133), of which 7,392 are pauses, leaving 146,741 phone (and closure) segments. Of the total of 12,114 deleted phones, 7,272 are non-released stop bursts, and 3,237 are closures. This is a substantial part of all deletions (86.8 %);
- 3. The one resulting from the actual automatic word or phone recognition (forced Viterbi).
2.1. Vowel duration distribution affected by stressing and location
short: /iy, ih, eh, ix, ax, ah, uw, uh/
long: /ae, aa, ao, ey, ay, oy, aw, ow, er/
The main effects of short vs. long vowels, stress and utterance-final lengthening are summarised in Table 1 together with data from Crystal & House [2]. All three effects (stress, vowel length, utterance position) are tangent and are potentially useful to improve automatic speech recognition performance.
TIMIT C. & H. TIMIT C. & H.
short V short long V long V
(8) V (4) (9) (7)
ms n ms n ms n ms n
uns 60 13,9 56 842 93 3,55 84 286
65 0
str 87 14,1 93 601 133 13,8 15 1,4
66 91 1 11
uf 78 1,19 81 39 109 408 11 7
uns 9 0
uf 14 954 14 78 177 1,13 20 125
str 2 7 5 2
unf 59 12,7 56 727 90 3,14 77 224
uns 66 2
unf 83 13,2 85 253 129 12,7 13 628
str 12 56 4
short vowel long vowel
unstres stressed unstress stressed
sed ed
ms n ms n ms n ms n
wf 71 5022 113 1268 97 1583 148 175
3
nwf 55 5858 82 4728 89 1679 123 540
2
mono 52 3085 86 8170 86 288 138 673
6
2.2. Effect of post-vocalic plosives on vowel duration
Similar to Van Santen, we limited ourselves to stressed vowels only. It was apparent that for the present database the distributions of vowels followed by voiced and unvoiced plosives are very similar indeed! Only the tails of the distributions give some indication of a lengthening effect for voiced plosives.
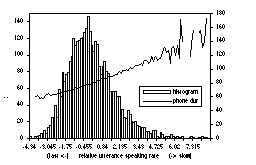
2.3. Effect of speaking rate on vowel duration
The normalised phone duration [4] is chosen as the basic unit, this way we correct for the intrinsically long or short duration of specific phones. The relative speaking rate of an utterance then is defined as the average normalised phone duration in that utterance. Actually this is more like the reciprocal of rate, since the higher that number the slower the rate. Fig. 2 gives a histogram distribution of the relative speaking rate for all 3,696 utterances. It is similar to the usual duration pdf of most phones, having a binomial-like distribution. For comparison, the utterance-averaged absolute phone durations in the corresponding histogram bins are also shown. It can be seen that the averaged absolute phone duration has a near-linear relation with the relative utterance speaking rate, this is particularly true in the middle region, where counts are large. The irregularities in the periphery are due to the fact that these represent relatively few utterances for which the intrinsic phone duration may vary a lot. We divided all sentences into the three categories fast, medium and slow, and derived phone duration distributions accordingly.
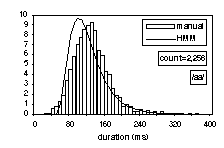
3. Hand-labelling vs. automatic segmentation
4. Analysis of variance
There is no straightforward ANOVA that can solve this problem, the complications lie at various levels: * the inability to model this complex factorial design in a fully satisfactory way;
* the sheer size of the data, which leads to memory problems;
* the problem of nested factors;
* empty cells and singletons;
* the ordering problem.
R speaking rate L syllable location
u in utterance
C broad phonetic G gender of speaker
l class
P phone D dialect region of
h r speaker
P phone in context S speaker
t p
S stress S phone segment
g
L syllable
w location in word
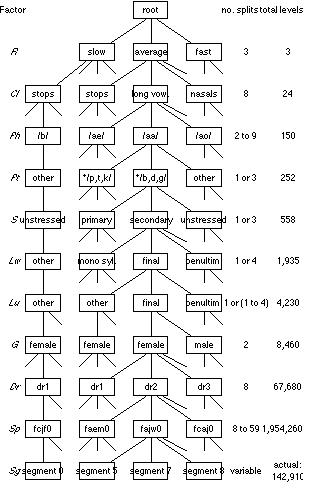
Each factor has a different number of levels and some of these numbers have complicated relations with others. The relations between all the levels in all the 11 factors can be shown in a tree, part of which is represented in Fig. 3.
The result of calculating the sum-of-squares (SS) terms in percentages in each of the subsequent 11 factors is shown in Table 3 for two different orderings of the factors. The most tangent phenomenon seen from these percentages is, that when Sp (and G and Dr) are put before Cl and Ph (see lower section of Table 3), the variation in Sp is rather small, while when Sp (and G and Dr) are put after the splitting of the data by Cl and Ph, Sp explains a much larger percentage of variation.
R Cl Ph Pt S Lw Lu G Dr Sp Sg los
s
2. 15 26 0. 0. 0. 0. 0. 2. 16 34 0.8
3 .1 .0 2 4 8 9 3 2 .0 .9
R G Dr Sp Cl Ph Pt S Lw Lu Sg los
s
2. 0. 0. 0. 19 37 1. 1. 1. 0. 34 0.7
3 0 0 6 .6 .5 1 2 5 6 .9
5. discussion
6. REFERENCES
- 1. Brugnara, F., Falavigna, D. & Omologo, M. "Automatic segmentation and labeling of speech based on hidden Markov models", Speech Comm. 12, 357-370, 1993.
- 2. Crystal, T.H. & House, A.S. "Segmental durations in connected-speech signals: Syllabic stress", J. Acoust. Soc. Amer. 83, 1574-1585, 1988.
- 3. Heuven, V.J. van & Pols, L.C.W. (Eds.) Analysis and synthesis of speech. Strategic research towards high-quality text-to-speech generation, Mouton de Gruyter, Berlin, 1993.
- 4. Jones, M. & Woodland, P.C. "Using relative duration in large vocabulary speech recognition", Proc. Eurospeech '93, Berlin, Vol. 1, 311-314, 1993.
- 5. Lamel, L.F. & Gauvain, J.L. "Identifying non-linguistic speech features", Proc. Eurospeech'93, Berlin, Vol. 1, 23-30, 1993.
- 6. Lee, K.-F. & Hon, H.-W. "Speaker-independent phone recognition using Hidden Markov Models", IEEE Trans. Ac. Speech and Signal Proc. ASSP 37, 1641-1648, 1989.
- 7. Nooteboom, S.G. Production and perception of vowel duration, Ph.D. Thesis, University of Utrecht, 1970.
- 8. Pallett, D.S., Fiscus, J.G., Fisher, W.M., Garofolo, J.S., Lund, B.A., Martin, A. & Przybocki, M.A. "1994 Benchmark tests for the ARPA Spoken Language Program", Proc. ARPA Spoken Language Systems Technology Workshop, Austin, TX, 5-36, 1995.
- 9. Peterson, G.E. & Lehiste, I. "Duration of syllable nuclei in English", J. Acoust. Soc. Amer. 32, 693-703, 1960.
- 10. Pols, L.C.W., Wang, X. & ten Bosch, L.F.M. "Modelling of phone duration (using the TIMIT database) and its potential benefit for ASR", Speech Communication (presented for publication), 1996.
- 11. Sun, D.X. & Deng, L. "Analysis of acoustic-phonetic variations in fluent speech using TIMIT", Proc. ICASSP-95, Detroit, 201-204, 1995.
- 12. Van Santen, J.P.H. "Contextual effects on vowel duration", Speech Comm. 11, 513-546, 1992.
- 13. Wang, X. Duration modelling in HMM-based speech recognition. Ph.D. thesis, University of Amsterdam, 1996, in prep.
- 14. Young, S.J. & Woodland, P.C. "The use of state tying in continuous speech recognition", Proc. Eurospeech'93, Berlin, Vol. 3, 2203-2206, 1993.