
The problem is the large amount of speech data needed to resolve interactions between factors. For independent factors, the number of "examples" needed to resolve them scales as the sum of their value levels. For interacting factors, the number of examples needed scales as the product of the number of factor levels. In practice it is nearly impossible to collect enough speech to cover all possible combinations of factor levels. Especially so because of factor confounding, the fact that some factor values have a low frequency in some contexts [14]. For example, in English, vowels occurring in word-initial syllables are much more likely to be stressed than vowels in word-final syllables; as a result, the former have a longer average duration than the latter. However, when properly analyzed, we find that word-final vowels are longer than word-initial vowels having the same stress level. Thus, the initial findings were deceptive.
It is to be expected that not all factors interact. The factors that affect segmental duration will be, in a first approximation, "piecewise independent" [14]. This means that we can divide the set of factors into non-overlapping sub-groups, such that interactions occur only between factors in a subgroup. This allows us to investigate segmental duration with less than complete coverage of all possible combinations of factor levels.
There are two types of speech corpus. In one, a carefully designed ("balanced") set of sentences is recorded with the property that factor confounding is minimized. However, this typically requires usage of repetitive carrier phrases, which may seriously undermine how naturally the text is read. In the other type (which we have used) naturally occurring meaningful sentences are used (c.f., [1],[2], [14]). This has the advantage of a more natural reading style, but the disadvantage of creating confounding. However, under the assumption of piecewise independence, we can analyze such data without strong concerns about factor confounding.
We used a new statistical method developed at Bell-Labs ([14-16]). This technique uses pairwise differences between "Quasi Minimal Pairs" to calculate "Corrected Means" that approximate the hypothetical balanced mean values, i.e., corrected with respect to the unbalanced distribution of realizations [14]. Non-parametric tests can be performed on the "Quasi Minimal Pairs" to determine the statistical significance of any effects found. These corrected means are then used to model the interactions between the relevant factors with respect to consonant duration.
Read aloud sentences of a male and a female speaker of American English were fully labeled and segmented by professional labelers. Both meaningful sentences and phonetically "rich" sentences were used for a total of 1206 sentences for the male speaker and 2951 for the female speaker. Only consonants from accented words were used from the female speaker. Word (or sentence) accent was not indicated reliably for the speech of the male speaker. Therefore, we ignored word accent for this speech and used both accented and unaccented words.
We used all VCV realizations of the 21 consonants /
![]() /. For practical reasons, glottal consonants, affricates and velar fricatives
were left out of the analysis. Each plosive was split in a closure and a
burst+aspiration part, for a total of 27 "types".
/. For practical reasons, glottal consonants, affricates and velar fricatives
were left out of the analysis. Each plosive was split in a closure and a
burst+aspiration part, for a total of 27 "types".
All intervocalic consonants (VCV, also crossing word boundaries) of non-clitics and non-sentence final words were isolated and analyzed. This resulted in 4380 VCV segments for the male speaker and 9606 VCV segments for the female speaker. All speech was recorded with a sampling frequency of 16 kHz and 16 bit resolution. Five factors were selected for investigation: Consonant identity, Syllable stress (Stressed or Unstressed), position in the word (Initial, Medial, and Final), word length (in syllables: 1, 2, 3, and more), and the frontedness of the syllabic vowel (as measured by F2: High, Middle, and Low F2, and Diphthongs).
The "Corrected Means" are calculated from the mean values of homogeneous subsets of realizations, i.e., sets for which the values of all five factors are equal. A table is constructed with the factor values for which the average is to be calculated as the row headings and all combinations of values of the other factors as column headings. Each cell contains the mean value of the "homogeneous" set of realizations that conform to the row and column factor values, e.g., there is a cell with the mean duration of all stressed, word-initial /n/ realizations from the male speaker which are followed by a High-F2 vowel in a three syllable word. For the data in our study, the table contains 27.2.3.4.4 = 2592 cells, 5184 if we pool the values of the two speakers. Less than one-third of these cells contains more than a single realization. Due to this extreme sparsity, standard statistical techniques (e.g., Factor Analysis, ANOVA, or MANOVA) will give results of only limited value (c.f., [1],[2]).
To handle this sparsity, we model segmental duration as: DUR(all factors)=A(row-factors)+B(column-factors), i.e., the duration as a function of all relevant factors is the sum of the effects of the row factors and the effects of the column factors [14]. That is, the influence of the row-factors is independent of the influence of the column factors. Under this assumption, the average, pair-wise, difference between corresponding cells in any two rows should only depend on the values of the row-factors involved, and not on the values of the column factors.
This way it is possible to calculate the average pair-wise cell differences between all pairs of rows, using only pairs of cells from the same column for which there are realizations in both rows. The differences are weighted to account the variation in the number of realizations in each cell, the weight being w=1/[radical](1/#Cell1 + 1/#Cell2). However, the exact form of the weighting function has little effect on the outcome, as long as the weights are related to the number of realizations in the cells.
The set of average differences between all pairs of rows constitutes a set of linear equations on the mean row values that can be solved using standard techniques (i.e., minimizing RMS-error with a Singular Value Decomposition, SVD). The results are the Corrected Mean durations of the rows, relative to the overall mean duration. For any fully balanced set of realizations, the result of this procedure would be identical to the raw means. Therefore, the corrected mean values can be interpreted as a least RMS-error approximation of "balanced" means with an unbalanced data set. The overall mean duration of all realizations from which the corrected means are calculated is used to transform the relative durations to absolute durations.
The original mean row differences are calculated from pair-wise cell differences. The non-parametric Wilcoxon Matched-Pairs Signed-Ranks test (WMPSR) is used to test the statistical significance of the differences. Each pair of table cells is used as a single matched pair in the analysis, i.e., we do not look "inside" the table cells.
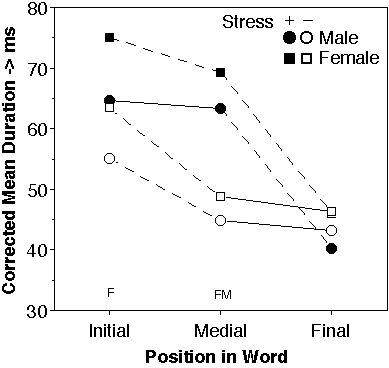
For both speakers we calculated the corrected mean durations of the consonants for each of the six combinations of syllable stress (stressed and unstressed) and position in the word (initial, medial, and final). The results are plotted in figure 1. The overall corrected mean difference between the speakers amounted to 8.44 ms. For both speakers we see that the stressed word-initial and word-medial consonants have similar durations and both are longer than stressed consonants from a word final position (p<=0.001, two-tailed WMPSR test). For consonants from unstressed syllables we see a different pattern. Unstressed consonants from a medial and final position in the word have similar durations and both differ markedly from unstressed consonants from a word-initial position. Moreover, in word-final position there is no difference in duration between stressed and unstressed consonants (p>=0.001, two-tailed WMPSR test).
For realizations from each position in the word, i.e., word-initial,
word-medial, and word-final, we determined the corrected mean difference
between stressed and unstressed realizations of each consonant. The values are
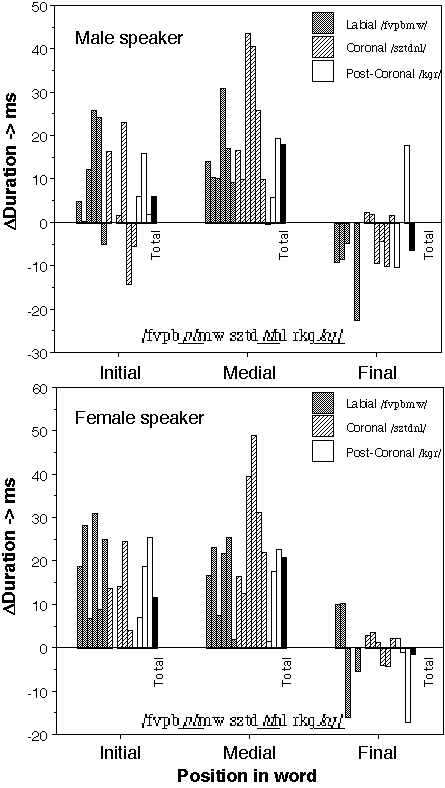
plotted in figure 2. It can be seen that the behavior found for all consonants
pooled is representative of the behavior of the individual consonants.
Differences between stressed and unstressed consonants are large in initial and
medial position and erratic in final position. The differences in the
size of the effect of stress on the corrected mean duration for each
consonant between initial, final and medial position are all statistically
significant (p<=0.002, two-tailed WMPSR test on the values of figure 2, both
speakers combined). However, it is also evident that the large influence of
syllable stress on consonants in word-medial position can be attributed to the
behavior of Coronal consonants, /
![]() / (word-medial versus word-initial, p<=0.001, two-tailed, WMPSR test, n=12).
Both for Labial and Post-Coronal consonants (i.e., Dorsal, Body, and Root
articulation combined), there is no real difference between consonant durations
in word-initial and word-medial position (p>0.05, n=16 and n=10). The
differences in duration between Coronal and Labial consonants are statistically
significant for the word-medial position (p<=0.001, two-tailed WMPSR test on
the values in figures 2, both speakers combined, n=16), but not for the
word-initial position, (p>0.05, n=12).
/ (word-medial versus word-initial, p<=0.001, two-tailed, WMPSR test, n=12).
Both for Labial and Post-Coronal consonants (i.e., Dorsal, Body, and Root
articulation combined), there is no real difference between consonant durations
in word-initial and word-medial position (p>0.05, n=16 and n=10). The
differences in duration between Coronal and Labial consonants are statistically
significant for the word-medial position (p<=0.001, two-tailed WMPSR test on
the values in figures 2, both speakers combined, n=16), but not for the
word-initial position, (p>0.05, n=12).
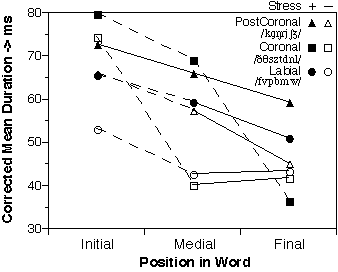
The differences due to the effect of the primary articulator are investigated by describing each phoneme by three values: Prime articulator (Labial, Coronal, Post-Coronal), Manner of Articulation (Fricative, Plosive stop, Plosive burst+aspiration, Nasal, and Vowel-Like), and voicing (for non-sonorants) and calculating the corrected means. The results for the primary articulator are summarized in figure 3.
There seem to be three "tiers" of duration: Long, Middle, and Short. The duration in each tier reduces from word initial to medial to final position. The differences between these three distinct durational tiers are statistically significant in word-initial and word-medial position. That is, there is a statistically significant difference between at least one member on one tier and one member on another tier in the same word position (p<=0.001, two-tailed WMPSR test) but no more than three tiers are found this way. Very weak evidence for two distinct durations can be found at the word-final position (i.e., p < 0.005 for only a single pair: Stressed Post-Coronals versus Stressed Coronals, two-tailed WMPSR test). However, all word-final durations might as well collapse into only a single value. This lack of resolution is most likely caused by a lack of data.
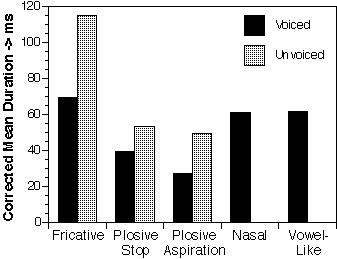
For completeness, we included the effect of manner of articulation and voicing which we found to be fairly independent of position in the word and stress. Figure 4 shows a quite simple behavior. All voiced consonants have comparable corrected mean durations (60-70 ms, combine the plosive stop durations and the burst + aspiration durations). Unvoiced consonants are about 40 ms longer than voiced consonants.
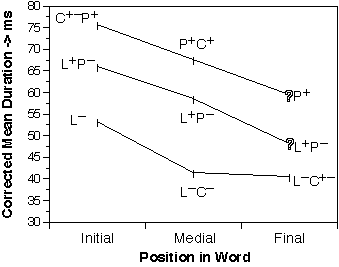
Consonants occupy the three tiers according to their prime articulator and
syllable stress. The Labial and Post-Coronal consonants behave regularly. The
stressed realizations occupy the higher tier, the unstressed realizations the
lower (Labials /
![]() / on the lower two tiers, Post-Coronals /
/ on the lower two tiers, Post-Coronals /
![]() / on the upper two).
/ on the upper two).
It is the Coronal consonants (/
![]() /) that behave irregularly. All word-initial and stressed word-medial Coronals
occupy the Long tier like the stressed Post-Coronals. The other Coronals occupy
the short tier like the unstressed Labials. This can be explained as a shift to
ballistic articulation. That is., the "reduced" Coronals are uttered
ballistically as very short flaps.
/) that behave irregularly. All word-initial and stressed word-medial Coronals
occupy the Long tier like the stressed Post-Coronals. The other Coronals occupy
the short tier like the unstressed Labials. This can be explained as a shift to
ballistic articulation. That is., the "reduced" Coronals are uttered
ballistically as very short flaps.
This strong interaction of factors might explain why the effects of Place-of-Articulation on plosive "hold" durations reported by Crystal and House [1] were so much smaller than ours. They used a representative sample of realizations, thereby "averaging out" most of the effect of the articulator.
We can conclude that it is possible to quantify and localize the interactions between factors affecting segmental durations using a normal, unbalanced speech corpus. It shows that the strongest dependencies exist with regard to word boundaries (word-initial versus final) and discontinuous changes in the articulation of Coronals.
This research was made possible by grant 300-173-029 of the Netherlands Research Organization (NWO)